| [ Team LiB ] |
|
Clustering Applications and ComponentsNow that we have our clustered environment installed and configured, we can get to the business of applying load balancing and providing failover for our applications and components. In a clustered environment, we can achieve failover protection and load balancing of our components and services, specifically
In this section, we will first take a look at the various available types of load balancing, and then we'll look at each of the failover and/or replication services provided to each in a WebLogic Server cluster. Load Balancing AlgorithmsThere are several algorithms that an object can use for load balancing. HTTP session state utilizes only round-robin, whereas RMI and EJB objects may use any of the algorithms:
The Clusterwide JNDI TreeBefore we get into any discussion of how objects are persisted in a cluster, we should mention how objects are addressed in a cluster. A WebLogic Server cluster provides a clusterwide JNDI tree that is replicated across all the servers participating in the cluster. Although the tree is replicated on multiple servers, it appears as a single tree to a client. The clusterwide JNDI tree is used to access both replicated and pinned objects. Pinned objects are those components that are hosted on a server that participates in a cluster, but is itself not replicated in the cluster. Because of this, if the server that hosts a pinned object goes down, the object will no longer be accessible to other servers in the cluster. For replicated objects, clients look up the object on the clusterwide JNDI tree and obtain its replica-aware stub (more on replica-aware stubs later in the chapter). The stub contains the list of server instances that hosting the object and based on its load-balancing algorithm connects the client to it. HTTP Session State ReplicationImagine, if you will, a Web application that provides online auto insurance. A customer is connected to the Web server hosting the application, filling out forms and continuing through a number of pages. The information gathered from this user is stored in an HTTP session object on the application server. Now imagine that as the user nears the completion of the forms, there is a server failure. What will happen to the user's information? Is his data lost for good? Must he start over and re-enter all of it? If so, will he become frustrated and give up, or worse, go to a competitor's Web site? Not if his session was replicated across other servers in a clustered domain! Web applications using servlets and JSPs achieve failover through replication of their HTTP session across the multiple servers in the cluster. Any server failure will appear transparent to the end user because his application will move to a backup server, grab the replicated session, and continue as though nothing had happened. HTTP sessions may be persisted in one of five different ways:
It is the memory-based replication across a cluster that is of interest to us, and we will cover that in detail, but before we go into the details, we'll go over the other four approaches to persistence and explain the pros and cons of each. None (Local Memory Session Persistence)Memory-based persistence on a single server really provides no persistence at all. The HTTP session information is stored only in that server's active memory. Performance is terrific, but the obvious drawback is that if the server should go down or run out of memory, the session information will be lost. To set memory-based persistence, you modify the WebLogic-specific deployment descriptor weblogic.xml. Under the <session-descriptor> element, set the PersistentStoreType property to memory, as in the following: <session-descriptor> <session-param> <param-name> PersistentStoreType </param-name> <param-value> memory </param-value> </session-param> </session-descriptor> File-Based Session PersistenceIn file-based session persistence, HTTP session information is written out to a file on the local workstation. Performance is not as good as in-memory persistence because it is writing session information to the disk, but you get good reliability. File-based persistence is configured in the WebLogic-specific deployment descriptor weblogic.xml. Under the <session-descriptor> element, set the PersistentStoreType property to file and define a persistent store directory for file output in the PersistentStoreDir property. The default directory is under the /WEB-INF directory of the Web application, although you can define any directory you want to with a relative or absolute path. The <session-descriptor> for file-based memory persistence might resemble the following: <session-descriptor> <session-param> <param-name> PersistentStoreDir </param-name> <param-value> session_db </param-value> <param-name> PersistentStoreType </param-name> <param-value> file </param-value> </session-param> </session-descriptor> CAUTION You must create the file output directory (/session_db in our example) manually under the /WEB-INF directory of your Web application because WebLogic will not do it for you! File-based persistence can also be made clusterable by sharing the output directory among the other servers in the cluster. JDBC-Based Session PersistenceIn JDBC-based session persistence, the HTTP session information is written to a JDBC-compliant database through a configured connection pool. Like file-based persistence, performance is a little less than in-memory persistence because it is writing to a database, but there is greater data integrity by having the session information in the database. To set JDBC-based memory persistence, you again modify the WebLogic-specific deployment descriptor weblogic.xml. Under the <session-descriptor> element, set the PersistentStoreType property to jdbc and name the persistent store pool you are using for data output in the PersistentStorePool property (this example uses MyConnectionPool), as in the following example: <session-descriptor> <session-param> <param-name> PersistentStorePool </param-name> <param-value> MyConnectionPool </param-value> <param-name> PersistentStoreType </param-name> <param-value> jdbc </param-value> </session-param> </session-descriptor> Cookie-Based Session PersistenceIn cookie-based session persistence, the session information is written out to a cookie file on the client's workstation. It offers no performance gain over server-side file-based persistence, but keeping the data on the client-side prevents data from filling up storage space on the server. The obvious drawback is that cookies must be enabled on the client's browser. This might work for an intranet application where you know the configuration of the browser, but might not work well on the World Wide Web. To configure cookie-based session persistence, you again modify the WebLogic-specific deployment descriptor weblogic.xml. Under the <session-descriptor> element, set the PersistentStoreType property to cookie and, optionally, name the cookie you are using for data output in the PersistentStoreCookieName property (this example uses SessionCookie), as in the following example: <session-descriptor> <session-param> <param-name> PersistentStoreCookieName </param-name> <param-value> SessionCookie </param-value> <param-name> PersistentStoreType </param-name> <param-value> cookie </param-value> </session-param> </session-descriptor> CAUTION Only String attributes may be stored in a cookie. Attempting to persist any other data object will throw an IllegalArgument exception! In-Memory Session Replication Across a ClusterNow we turn our attention to the most robust and fastest option for HTTP session replication: persistence across managed servers in a cluster. To whichever server the client first connects, a primary session state is created and stored in that server's memory. A replica session state is then created and stored in the memory of a second server instance in the cluster. Through a process called in-memory replication, the two sessions are kept concurrent. If the host server fails, the primary session fails over to the secondary session and the client proceeds unaware of the change. The following paragraphs will show you how to use in-memory session replication in a cluster to make your Web component sessions persistent. First, your Web components must be serializable, so you must make all of your Web components implement the java.io.Serializable interface. Next, you must set up WebLogic Server to access the cluster via a proxy. There are three ways to doing this:
If you are using the HttpClusterServlet, you can configure the load-balancing algorithm from within the Administration Console, as defined earlier in the chapter. If you are using a third-party plug-in or a hardware solution, you can use the load-balancing tools provided with these servers. Finally, we configure the application to use in-memory session replication across a cluster. In a text or XML editor, open the WebLogic-specific deployment descriptor weblogic.xml. Under the <session-descriptor> element, set the PersistentStoreType property to replicated, as in the following example: <session-descriptor> <session-param> <param-name> PersistentStoreType </param-name> <param-value> replicated </param-value> </session-param> </session-descriptor> EJB and RMI Components via Replica-Aware StubsIn a clustered environment, EJB and RMI objects are replicated and hosted on each server. When a client wants to access one of these objects, how does it know on which server to connect? The answer lies in the replica-aware stub. Unlike a single-server environment, when a client connects to a clustered component, it is really connecting to its replica-aware stub. The replica-aware stub holds the logic to redirect the client to an EJB or RMI object on one of the servers in the cluster, based on some load-balancing algorithm. If the stub is unable to connect to one of the servers, it redirects to another and repeats the call. Let's first take a look at how to create replica-aware stubs for our objects, and then how to configure WebLogic Server to use them in a cluster. Compiling RMI Objects to Support ClusteringFor an RMI object to support clustering, we have to compile it to create the necessary replica-aware stubs. This is done with the WebLogic RMI compiler tool, weblogic.rmic. The following example shows a command to create replica-aware stubs for an RMI object, MyRMIObject: java weblogic.rmic clusterable packagename.MyRMIObject You might want to also declare additional parameters in your object, such as declaring that it is idempotent: java weblogic.rmic clusterable methodsAreIdempotent packagename.MyRMIObject When we declare an object idempotent, we are stating that if the object's method is called repeatedly, the outcome will be the same as if the method had been called only once. For instance, you would want an object that withdraws money from an account to do so only once, even if the method were called a number of times during a network or server failure. Using methodsAreIdempotent allows the RMI stubs to fail over and use load balancing. If you skip this option (if at least one method in the interface is not idempotent, you should not use it), the stub will not fail over, but will still use load balancing. We might also want to implement the CallRouter interface as a way of ascribing a load-balancing algorithm to the object:
java weblogic.rmic clusterable callRouter packagename.MyRMIObject
The CallRouter interface is described in the WebLogic Cluster API. It is invoked by the clusterable stub each time a remote method is called. The interface allows the router to determine the server to which the call should be routed programmatically. For more information on using the weblogic.rmic compiler tool, consult the BEA documentation at http://edocs.bea.com/wls/docs81/rmi/rmi_program.html. Compiling EJB Objects to Support ClusteringThe weblogic.appc compiler utility is used to create remote stubs for EJBs to be deployed in a cluster. Unlike the compilation for RMI components, replica-aware stubs will be automatically created if they are described in the EJB's deployment descriptor. Additional parameters, such as idempotence or the use of a CallRouter, may also be described in the deployment descriptor. When weblogic.appc is run on the component, these attributes are read from the weblogic-ejb-jar.xml file and automatically generated by the compiler. For more information about using the weblogic.appc compiler tool, consult the BEA documentation at http://e-docs.bea.com/wls/docs81/ejb/implementing.html#1125457. Clustering JDBC ConnectionsAlthough WebLogic Server does not supply specific failover capabilities for JDBC connections, it does not mean that clustering for JDBC objects is not entirely unsupported. Through the use of connection pools and multipools, we can achieve some load-balancing functionality. The steps are as follows:
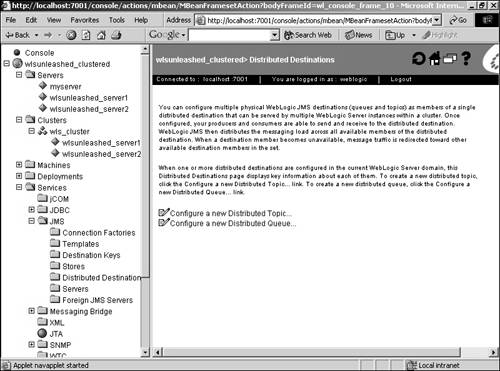
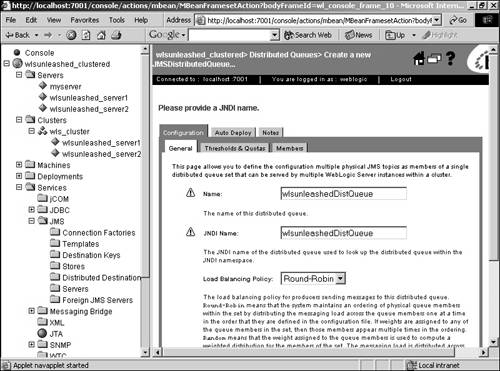
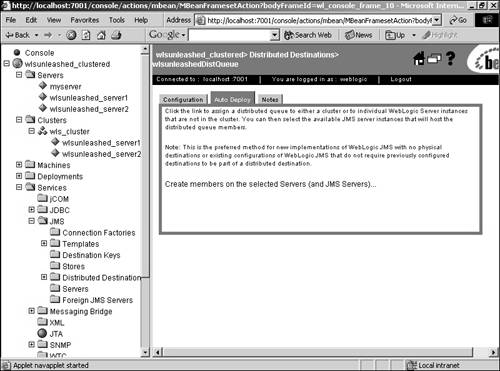
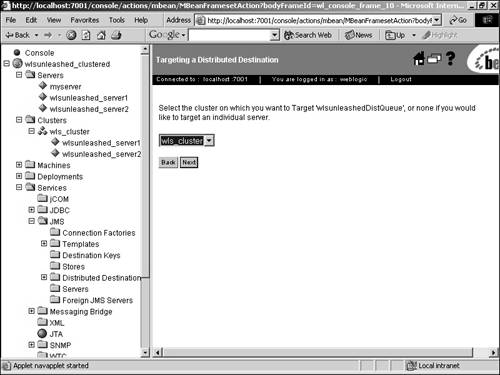
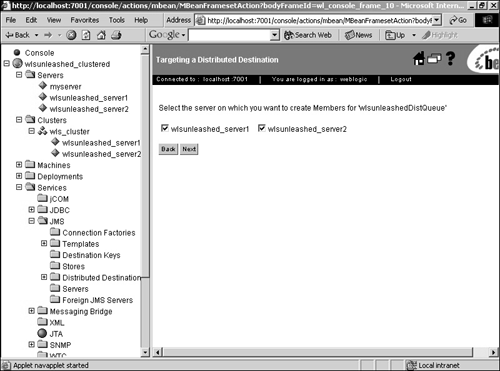
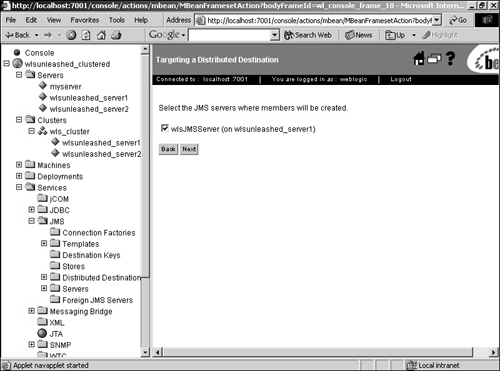
Now we have a load-balancing multipool configured. When a connection is requested, the data source accesses the connection pool from the multipool list in a round-robin order, instead of always calling the first connection pool in the list. The load-balancing multipool also offers some failover support, but only prior to the start of a transaction. If the WebLogic Server instance that is already hosting the JDBC connection fails, any transaction in progress will roll back and the application will need to reconnect to the data source and start again. What multipools can do, however, is redirect us to the next connection pool in the list if the one it first tries to access is down. HTTP Sessions and ClustersHTTP sessions can be configured to replicate to other servers in the cluster, thereby offering failover for servlet session states. When a servlet session is initiated using the HttpSession.getSession() call, the session is created on the server to which the client connected. This is the primary session state and it is also replicated to a secondary server in the same WebLogic cluster. The secondary replica is kept up to date for any unforeseen failures and can be used if the primary server of the client fails. The secondary server is chosen by WebLogic Server and, by default, it tries to create the replica in a server that is not in the same physical machine as that of the primary server. Alternatively, cluster groups can be created and can be used to control the creation of secondary replicas in the server or server group you want. To leverage in-memory replication of session state, servlets have to be accessed using either a Web server farm running WebLogic proxy plug-ins or a load director. In the first alternative, the proxy maintains information about the servers in the WebLogic cluster that hosts the Web application, and takes care of forwarding the requests to these instances using a round-robin strategy along with failover logic to identify the secondary replica in case the primary server fails. Clustering WebLogic JMSEarlier releases of WebLogic provided no clustering capabilities for JMS. Starting with WebLogic Server 7.0, there is failover support for JMS by enabling you to create and distribute your queue and topic messages across multiple destinations. If one server instance fails, traffic is diverted to the remaining destinations. Configuration of a new distributed destination is done within the Administration Console. The following example will walk you through the creation of a topic:
The creation of distributed topics destinations is similar to what we have just shown for queues. Consult the BEA documentation for more details: http://e-docs.bea.com/wls/docs81/jms/implement.html#1260801. |
| [ Team LiB ] |
|