| only for RuBoard - do not distribute or recompile |
Entity-relationship (ER) modeling is a simple and clear method of expressing the design of database. ER modeling isn't newit was first proposed by Chen in 1976but it has only emerged as the dominant modeling paradigm for databases in the past 10 or 12 years.
Figure C-2 shows a partial model of the winestore. In this diagram, you can see the relationship between wines, wineries, and regions. Each wine has attributes such as a name, type, and a description. A wine is made by a winery, and each winery has attributes such as a name, phone, and description. Many wineries are located in a region, where a region has a map and description.
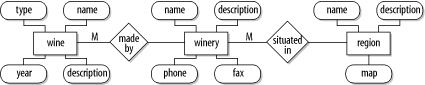
ER diagrams aren't complicated, and we have already illustrated most of the features of ER modeling in Figure C-2. These features include:
Represent entitiesthat is, objects being modeled. Each entity is labeled with a meaningful title.
Represent relationships between entities; a relationship is labeled with a descriptive title that represents how the entities interact.
Represent attributes that describe an entity.
Connect entities to relationships. Lines may be without any annotation, be annotated with an M and an N, or annotated with an M and a 1 (or an N and a 1). Annotations indicate the cardinality of the relationship; we discuss cardinality later in this section.
Connect attributes to entities. These lines are never labeled.
Other ER modeling tools include double ellipses, dashed ellipses, and double lines; we use some of these advanced features later in this appendix. Useful references for more advanced ER modelingand enhanced ER (EER) modelingare provided in Appendix E.
To illustrate how ER modeling can be used to effectively design a database, we return to our online winestore.
The first step in developing a database model using ER modeling is to consider the requirements of the system. The requirements for the online winestore were described in Chapter 1 and are typically gathered from a scope document, customer interviews, user requirements documents, and so on.
Many of the requirements affect development of the ER model, while others are more general system requirements used to develop the web database application. One of the skills of ER modeling is extracting the requirements that impact on the database design from those that are functional elements of the system.
Once a system requirements analysis is complete, and the detailed requirements written down, you can proceed to the conceptual database design using the ER modeling techniques.
Having identified the general requirements of the system, the first phase in conceptual modeling and creating an ER model is to identify the entities in the system.
Entities are objects or things that can be described by their characteristics. As we identify entities, we list the attributes that describe the entity. For example, a customer is an entity that has a name, an address, a phone, and other details.
|
Five entities and their attributes have already been identified earlier in this appendix. Four are easy to determine from our requirements:
The wine entity has the attributes type, name, year, and description.
The customer entity has the attributes surname, firstname, initial, title, addressline1, addressline2, addressline3, city, state, zipcode, country, phone, fax, salary, birthdate, email address, and discount.
The winery entity has the attributes name, description, phone, and fax.
The region entity has the attributes name, description, and map.
We add a users entity to this list in order to maintain user account details at the winestore:
The users entity has the attributes user_name and password. The user_name is the same as the customer email address.
The remaining entitiesand, in two cases, the distinction between the entitiesare harder to identify.
We have earlier identified the order entity in our introduction to ER modeling, but an order is hard to precisely define. One description might be:
An order is an object created by a customer when they agree to purchase one or more (possibly different) bottles of wine.
We can then say that an order is created on a date, and the system requirements in Chapter 1 identify that an order has a discount, a delivery cost, and a delivery note.
We can also say that this model of an order consists of one or more different wines and, for each different wine, a quantity of that wine is purchased. The subparts in each orderthe different kinds of winesare the items that make up the order. But is the wine itself part of an item? The distinction is hard, but the correct answer is probably no: this is a relationship, the items that make up an order are related to wines.
There are now two more entitiesorders and itemsand two relationships, which illustrates how difficult it is to reason about entities without considering how they are related. Determining entities isn't always easy, and many different drafts of an ER model are often required before a final, correct model is achieved. The ER model for the winestore took several attempts to get right.
Here are the item and order entities:
The item entitywhich is related to an orderhas the attributes quantity and price.
The order entity has attributes date, discount percentage, delivery cost, and delivery note.
The system requirements in Chapter 1 showed that wines are delivered in shipments. Each shipment is on a date and consists of a number of bottles, at a per-bottle and per-case price. How is this incorporated into the model? Perhaps the most obvious solution is to add quantity and price attributes to the wine entity. This doesn't work well: it is difficult to maintain the possibly different prices for different shipments and to maintain the correct shipment dates.
A good solution to the inventory problem is an inventory entity. This entity is related to the wine, and maintains different sets of data for each shipment of each wine:
The inventory entity has an on-hand quantity, an item cost, a dateadded, and a case cost (for a dozen bottles).
The final entity is somewhat of an oddity. If a wine is a Cabernet Merlot, you can simply store the string Cabernet Merlot in an attribute in the wine entity. Another approach is to have a grape_variety entity, where each different grape variety is described individually. So, Cabernet is one instance of a grape_variety entity, and Merlot is another. The grape_variety entity is then related to the wine entity. This approach does seem overly complicated, but let's opt for it anyway because it introduces an instructive twist to our modeling, a many-to-many relationship discussed in the next section.
Let's add two attributes to the grape_variety entity, variety (the description) and ID (a counter used to, for example, record that Cabernet is the first word in Cabernet Merlot, and Merlot is the second word.
The grape_variety entity has two attributes, ID and variety.
There are other possible entities. For example, the shopping basket could be an entity: the shopping cart is an object that contains items that will be ordered. However, a shopping cart is an incomplete order and, hence, it's omitted from the entity list. Including it is perhaps valid, and depends on how the entities are interpreted from the requirements.
There are also other entities that are outside the scope of our requirements. For example, a country might contain many regions, but there is no requirement for countries to be modeled in our system. Also, the winestore itself is an entity, but we are actually interested in the entities that make up the winestore, not really the whole concept itself. Selecting entities is all about getting the granularity and scope of choice right.
We have hinted at but not explicitly identified the relationships between the entities. For example, a winery is part of a region, a wine is made by a winery, and an item is related to a wine. The first step is to identify the entities and their attributes; the second step is to identify how the entities are related.
Before identifying the relationships between the entities we have identified, we noted earlier in this section that:
Lines connect entities to relationships. Lines may be without any annotation, be annotated with an M and an N, or annotated with an M and a 1 (or an N and a 1). Annotations indicate the cardinality of the relationship.
Cardinality refers to the three possible relationships between two entities[A] and, before you can consider how the entities are related, you need to explore the possible kinds of relationship:
[A] Actually, relationships can exist between as many entities as there are in the model. Also, we have deliberately omitted the distinction with relationships that are optional, that is, where one instance of an entitysuch as a customercan exist without a related entitysuch as an order. However, we avoid complex relationships in this appendix; more detail can be found in the books listed in Appendix E.
A one-to-one relationship is represented by a line without any annotations that joins two entities. One-to-one means that for the two entities connected by the line, there is exactly one instance of the first entity for each one instance of the second entity. An example might be customers and user details: each customer has exactly one username and password, and that particular username and password is only for that customer.
A one-to-many relationship is represented by a line annotated with a 1 and an M (or a 1 and an N). One-to-many means that for the two entities connected by the line, there are one or more instances of the second entity for each one instance of the first entity. From the perspective of the second entity, any instance of the second entity is related to only one instance of the first entity. An example is wineries and wines: each winery sells many wines, but each wine is made by exactly one winery. Many-to-one relationships are the most common relationships between entities.
A many-to-many relationship is represented by a line annotated with an M and an N. Many-to-many means that for the two entities connected by the line, each instance of the first entity is related to one or more instances of the second entity and, from the other perspective, each instance of the second entity is related to one or more instances of the first entity. An example is the relationship between wineries and delivery firms: a winery may use many delivery firms to freight wine to customers, while a delivery firm may work for many different wineries.
It isn't surprising that many database modelers make mistakes with cardinalities. Determining the cardinalities of the relationships between the entities is the most difficult skill in ER modeling, but one that, when performed correctly, results in a well-designed database. To illustrate how cardinality is determined, let's consider the relationships between the entities in the winestore and present arguments for their cardinalities.
|
Before considering cardinalities, you need to consider what entities are related. You know from previous discussion that a region is related to a winery, and that a winery is related to a wine. There are other relationships that are implicitly identified: an order contains items, a customer places an order, users have customer details, and a wine has an inventory.
There is also one crucial relationship that links the wines sold to the customer, that is, the relationship between an order item and the inventory. Last, a wine contains one or more different grape variety entities.
To assign cardinalitieswhich crucially affect the database designstart with the relationship of wines to wineries. To begin, you need to decide what sort of relationship these entities have and assign a descriptive term. A good description of the relationship between wines and wineries is that a winery makes wine. Now draw a diamond labeled makes between the entities wine and winery, and connect the relationship to the two entities with an unannotated line. This process is shown in Figure C-3 (A).
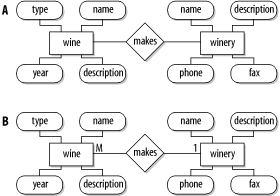
The next step is to determine what cardinality to assign to this relationship. The most effective approach to determining cardinality is to consider the relationship from the perspective of both entities. From the perspective of a winery, the question to ask is:
Does a winery make exactly one wine or one or more wines?
The answer is the latter, so you write M at the wine-end of the relationship. From the other perspectivethat of the wineyou can ask a second simple question:
Is a wine made by exactly one or more than one winery?
This answer is the formerthat limitation is noted in the system requirementsand you can write a 1 at the winery-end of the relationship. The annotated, one-to-many relationship is shown in Figure C-3 (B).
Dealing with the relationship between wineries and regions involves similar arguments. You begin by describing the relationship. In this case, an appropriate label might be that a winery is situated in a region. After drawing the diamond and labeling it, now consider the cardinalities. A winery belongs in exactly one region, so label the region end with a 1. A region contains one or more wineries, so you label the winery end with an M.
There are three more relationships that can be completed using the same one-to-many arguments:
The consists-of relationship between orders and items
The purchase relationship between customers and orders
The stocked relationship between wines and inventories
You can label all three with a 1 and an M (or N). The consists-of relationship is labeled with a 1 at the order end and an M at the item end. The purchase relationship is labeled with an M at the order end and a 1 at the customer end. The stocked relationship is labeled with an M at the inventory end and a 1 at the wine end. These relationships are shown as part of Figure C-4.
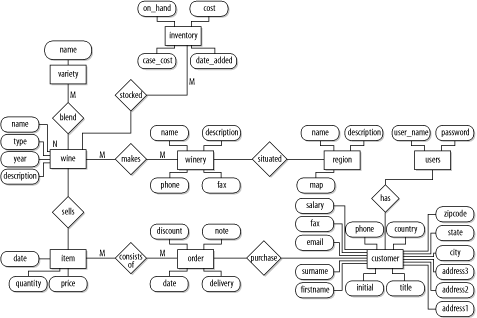
You know that the users and customer have a one-to-one relationship. Now draw a line between the two entities and label it with a 1 at each end. Label the relationship as has. You can also add the password attribute to the customers entity and omit the users entity altogether. However, to fully illustrate the different features of ER modeling, let's maintain the separation between customer and users entities.
The final two relationships are a more difficult to identify and annotate.
The first is the relationship between an order item and a wine. The one-to-many cardinality isn't a difficult proposition, but determining that this relationship actually exists is harder. When considering what makes up an order, there are two possibilities: an item can be related to a specific inventory entry, or an item can be related to a wine. The former is possibly more intuitive because the item that is delivered is a bottle from our inventory. However, the latter works better when modeling the system's data requirements.
In our design, a customer order is made up of quantities of wines. You can label this relationship as sells. The price of the wine is copied from the inventory and stored in the order. This design is appropriate because the relationship between a customer and a specific bottle is uninteresting once the order is shipped and, arguably, it is uninteresting even as the order is packed.
The second difficultand finalrelationship is that between wines and grape varieties. Naming the relationship is easy: let's call this relationship blend. Determining the cardinality is harder. First, consider the relationship from the wine perspective. A wine can contain more than one grape variety when it is a blend, so you label the grape variety end of the relationship with an M. Now consider the relationship from the grape variety perspective. A grape variety, such as semillon, may be in many different wines. So, let's settle on a many-to-many relationship and label the wine end with an N.
Our ER model is almost complete, and Figure C-4 shows it with all its entities and relationships. What remains is to consider the key attributes in each of the entities, which are discussed in the next section. As you consider these, you can adjust the types of relationships slightly.
There are a few rules that determine what relationships, entities, and attributes are, and what cardinalities should be used:
Expect to draft a model several times.
Begin modeling with entities, add attributes, and then determine relationships.
Include an entity only when it can be described with attributes that are needed in the model.
Some entities can be modeled as attributes. For example, a country can be an entity, but it might be better modeled as one of the attributes that is part of an address.
Avoid unnecessary relationships. Only model relationships that are needed in the system.
One-to-one relationships are uncommon. If two entities participate in a one-to-one relationship, check that they aren't actually the same entity.
Many-to-many relationships are complex. Use one-to-many relationships in preference where possible.
In our introduction to ER modeling, we noted some of the implicit constraints of our model, including that there is only one customer #37 and one wine that we refer to as #168. In the model design so far, we haven't considered how to uniquely identify each entity.
Uniqueness is an important constraint. When a customer places an order, you must be able to uniquely identify that customer and associate the unique order with that unique customer. You also need to be able to uniquely identify the wines the customer purchases. In fact, all entities must be uniquely identifiable; this is true for all relational databases.
The next step is to identify the attributes or sets of attributes that uniquely identify an entity. Begin with the customer. A surname (or any combination of names) doesn't uniquely identify a customer. A surname, firstname, initial, and a complete address may work, although there are some cases where children and parents share the same name and address.
A less complicated approach for unique identificationand a common one that's guaranteed to workis to add an identifier number (ID) attribute to the entity. A short unique identifier also leads to better database performance, as discussed in Chapter 3. Using this approach, assign ID #1 to the first customer, ID #2 to the second customer, and so on. In the model, this new attribute is underlinedto indicate that it uniquely identifies the customer as shown in Figure C-5.
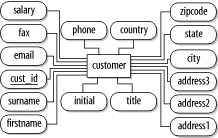
You can take the same approach with wine as for customersfor the same reasonsand add an ID field.
For wineries and regions, the name is most likely unique or, at least, it can be made so. However, for simplicity, you should also use the ID attribute approach to prevent any ambiguity or need for the winestore administrator to create unique names for wineries or regions. The same argument can be applied to grape varieties.
Orders can also be dealt with by a unique ID, as can items and inventory. However, the uniqueness of this ID may be questionable. To illustrate, consider an example. You can number each order across the whole system uniquely, beginning with the system's first order #1. Alternatively, you can combine the customer ID with an order ID and begin each different customer's orders with order ID #1. The combination of customer ID and order ID is still unique, e.g., customer #37, order #1 is different from customer #15, order #1. This latter scheme is an example of a full participation relationship by a weak entity: an order isn't possible without a customer (hence, the term full participation) and the customer ID forms part of the order entity's unique identifier, hence the term weak entity.
You can use the scheme of full participation by a weak entity for orders; the other approach of numbering orders across the whole collection also works well. An advantage of this scheme is that the order number is more meaningful to the userfor example, a user can tell from their order number how many orders they have placedand the order number provides a convenient counting tool for reporting. Participation is discussed briefly in the next section and weak entities are discussed in more detail later in Section C.2.1.7.
You can follow similar arguments with items. An item can be uniquely numbered across the whole system or can be numbered from #1 within an order. Again, this depends on the participation and, as with orders, we follow the latter approach. The same applies for inventory, which is numbered within a wine.
Because customer and users have a one-to-one relationship, the customer ID can be used to uniquely identify a user. Therefore, the users entity has full participation as a weak entity in the relationship with customer.
Other ER modeling tools include double ellipses and double lines. These tools permit the representation of other constraints, multivalued attributes, and the specification of full participation. In addition, it is possible for a relationship to have an attribute, that is, for a diamond to have attributes that are part of the relationship, not part of the entities. Useful references for more advanced ER modelingand enhanced ER (EER) modelingare provided in Appendix E.
Double lines as relationships indicate full participation and represent cases where an instance of one entity can't exist without a corresponding instance of the entity that it is related to. An example is an order as discussed in the previous section. An order can't exist without a customer to make that order. Therefore, correctly, the relationship between order and customer should be represented as a double line; the same constraints apply in the model to items and inventories.
Dashed ellipses represent multivalued attributes, attributes that may contain more than one instance. For example, the attribute address can be multivalued, because there could be a business address, a postal address, and a home address. Multivalued attributes aren't used in our model.
In addition, there are other extensions to the modeling techniques that have already been applied. For example, more than two entities can be related in a relationship (that is, more than two entities can be connected to a diamond). For example, the sale of a wine can be described as a three-way relationship between a wine, a customer, and an order. A second complex technique is the composite attribute; for example, an attribute of customer is address and the attribute address has its own attributes, a street, city, and zipcode. We don't explore complex relationships in this book.
Figure C-6 shows the final ER model with the unique key constraints shown. Notice that for items, orders, users, and inventories, the attributes from other entities aren't included. They are instead indicated as weak entities with a double rectangle and they participate fully in the related entities as indicated by double lines.
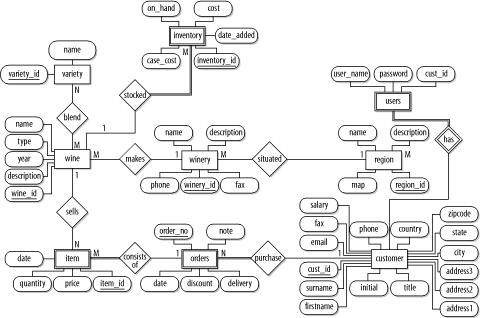
If items, orders, and inventories are numbered across the whole system, you can omit the double rectangles. The double lines can be omitted if any entities can exist without the related entity.
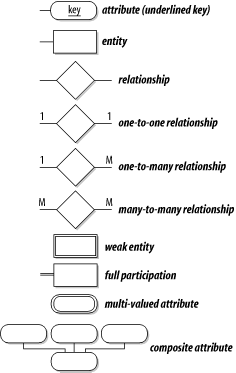
A summary of ER notation tools is shown in Figure C-7.
There are five steps to convert an ER model to a set of SQL CREATE TABLE statements.
The first step is the simplest. Here's what you do:
For each non-weak entity in the ER model, write out a CREATE TABLE statement with the same name as the entity.
Include all attributes of the entity and assign appropriate types to the attributes.
Include the PRIMARY KEY of the entity.
Add any modifiers to attributes and any additional keys as required.
To perform this step, you need to make decisions about attribute types in the SQL CREATE TABLE statements. Attribute types are discussed in Chapter 3.
There are several non-weak entities in the model. Begin with the region entity, which has the attributes region_id, region_name, description, and map. You might anticipate no more than 100 different regions, but being cautious is important if more than 1,000 regions need to be stored. Accordingly, a type of int(4) allows up to 10,000 regions. Using a similar argument, define region_name as a varchar(100). Because descriptions may be long, let's define description as a blob. A mapwhich is an imageis defined as a mediumblob.
As decided earlier in the chapter, the unique key of the region table is an ID, which is now called region_id. Accordingly, you define a PRIMARY KEY of region_id. A requirement of all primary keys is that they are specified as NOT NULL, and this is added to the attribute. Now automate the creation of the values by adding the auto_increment clause and a DEFAULT '0'. (Recall from Chapter 3 that storing NULL or 0 in an auto_increment attribute is a MySQL feature that automatically stores a unique ID larger than all other IDs for this table.)
The resulting definition for the region table is then as follows:
CREATE TABLE region ( region_id int(4) DEFAULT '0' NOT NULL auto_increment, region_name varchar(100) DEFAULT '' NOT NULL, description blob, map mediumblob, PRIMARY KEY (region_id), KEY region (region_name) );
Notice an additional KEY on the region_name named region. By adding this key, you anticipate that a common query is a search by region_name. Also, a region must have a name, so a NOT NULL is added to the region_name attribute.
The CREATE TABLE statements for the other non-weak entities are listed in Example C-1. Remember, however, that this is only the first step: some of these CREATE TABLE statements are altered by the processes in later steps.
CREATE TABLE wine ( wine_id int(5) DEFAULT '0' NOT NULL auto_increment, wine_name varchar(50) DEFAULT '' NOT NULL, type varchar(10) DEFAULT '' NOT NULL, year int(4) DEFAULT '0' NOT NULL, description blob, PRIMARY KEY (wine_id) ); CREATE TABLE winery ( winery_id int(4) DEFAULT '0' NOT NULL auto_increment, winery_name varchar(100) DEFAULT '' NOT NULL, description blob, phone varchar(15), fax varchar(15), PRIMARY KEY (winery_id) ); CREATE TABLE customer ( cust_id int(5) NOT NULL auto_increment, surname varchar(50) NOT NULL, firstname varchar(50) NOT NULL, initial char(1), title varchar(10), addressline1 varchar(50) NOT NULL, addressline2 varchar(50), addressline3 varchar(50), city varchar(20) NOT NULL, state varchar(20), zipcode varchar(5), country varchar(20), phone varchar(15), fax varchar(15), email varchar(30) NOT NULL, birth_date date( ), salary int(7), PRIMARY KEY (cust_id), KEY names (surname,firstname) ); CREATE TABLE grape_variety ( variety_id int(3), variety_name varchar(20) PRIMARY KEY (variety_id) );
The second step is almost identical to the first but is used for weak entities. Here's what you do:
For each weak entity in the modelthere are three: inventory, order, and itemtranslate the entity directly to a CREATE TABLE statement as in Step 1.
Include all attributes as in Step 1.
Include as attributes the primary key attributes of the owning entity; that is, the entity the weak entity is related to. These attributes are in the table and are also included as part of the primary key of the weak entity.
For example, for the inventory entity, create the following:
CREATE TABLE inventory ( wine_id int(5) DEFAULT '0' NOT NULL, inventory_id int(3) NOT NULL, on_hand int(5) NOT NULL, cost float(5,2) NOT NULL, case_cost float(5,2) NOT NULL, dateadded timestamp(12) DEFAULT NULL, PRIMARY KEY (wine_id,inventory_id) );
The wine_id is included from the wine table and forms part of the PRIMARY KEY definition. All attributes can't be NULL in this inventory table, so you'll note liberal use of NOT NULL. The dateadded attribute has a DEFAULT NULL, which if no value is inserted, is automatically filled with the current date and time.
A similar approach is taken with orders, in which cust_id is included from the customer table as an attribute and as part of the PRIMARY KEY definition:
CREATE TABLE orders ( cust_id int(5) DEFAULT '0' NOT NULL, order_id int(5) DEFAULT '0' NOT NULL, date timestamp(12), discount float(3,1) DEFAULT '0.0', delivery float(4,2) DEFAULT '0.00', note varchar(120), PRIMARY KEY (cust_id,order_no) );
The items table is slightly more complex, but made easier because orders has already been defined. The items table includes the PRIMARY KEY attributes of the entity it is related to (that is, orders). Because the PRIMARY KEY of orders is already resolved, the resolution is as follows:
CREATE TABLE items ( cust_id int(5) DEFAULT '0' NOT NULL, order_id int(5) DEFAULT '0' NOT NULL, item_id int(3) DEFAULT '1' NOT NULL, qty int(3), price float(5,2), date timestamp(12), PRIMARY KEY (cust_id,order_no,item_id) );
There is a one-to-one relationship between customer and users in our model. The process for conversion is as follows:
Choose one of the two tables that participates in the relationship (this table has already been identified and written out as part of Steps 1 or 2). If the relationship involves total participation, choose the entity that totally participates.
In the chosen table, include as an attribute (or attributes) the primary key of the other table.
If the entities totally participate in each other and neither participates in another relationship, consider removing one of the tables and merging the attributes into a single table.
As users is the entity that totally participates in customer, the identifier cust_id from customer is added to the users table and defined as the primary key attribute:
CREATE TABLE users ( cust_id int(4) DEFAULT '0' NOT NULL, user_name varchar(50) DEFAULT '' NOT NULL, password varchar(15) DEFAULT '' NOT NULL, PRIMARY KEY (user_name), );
For a regular one-to-many relationship, here's the procedure:
Identify the table representing the many (M or N) side of the relationship.
Add to the many-side (M or N) table the primary key of the 1-side table.
Optionally, add NOT NULL to any attributes added.
In the model, this means adding a winery_id to the wine table:
CREATE TABLE wine ( wine_id int(5) DEFAULT '0' NOT NULL auto_increment, wine_name varchar(50) DEFAULT '' NOT NULL, winery_id int(4), type varchar(10) DEFAULT '' NOT NULL, year int(4) DEFAULT '0' NOT NULL, description blob, PRIMARY KEY (wine_id) );
For the winery table, it means adding a region_id:
CREATE TABLE winery ( winery_id int(4) DEFAULT '0' NOT NULL auto_increment, winery_name varchar(100) DEFAULT '' NOT NULL, region_id int(4), description blob, phone varchar(15), fax varchar(15), PRIMARY KEY (winery_id) );
The final regular one-to-many relationship is between wine and item. For this, add a wine_id to items:
CREATE TABLE items ( cust_id int(5) DEFAULT '0' NOT NULL, order_id int(5) DEFAULT '0' NOT NULL, item_id int(3) DEFAULT '1' NOT NULL, wine_id int(4) DEFAULT '0' NOT NULL, qty int(3), date timestamp(12), price float(5,2), PRIMARY KEY (cust_id,order_no,item_id) );
In cases where you wish to prevent a row being inserted without a corresponding value, you can add a NOT NULL to the attribute added in this step.
For many-to-many relationshipsthere is one in our model between wine and varietythe following procedure is used:
Create a new table with a composite name made of the two entities that are related.
Add the primary keys of the two related entities to this new table.
Add an ID attribute if the order of relationship is important. For example, in the winestore, a Cabernet Merlot Shiraz is different from a Shiraz Merlot Cabernet, so an ID is required.
Define the primary key of this new table to be all attributes that form part of the table.
In the example, create the following table:
CREATE TABLE wine_variety ( wine_id int(5) DEFAULT '0' NOT NULL, variety_id int(3) DEFAULT '0' NOT NULL, id int(1) DEFAULT '0' NOT NULL PRIMARY KEY (wine_id, variety_id) );
The table contains the primary keys of the wine and grape_variety and defines thesealong with the ID attributeas the PRIMARY KEY. No change is required to the wine or grape_variety tables.
| only for RuBoard - do not distribute or recompile |
