|
|
|
5.2 Parrot's ArchitectureThe Parrot system is divided into four main parts, each with its own specific task. The diagram in Figure 5-1 shows the parts, and the way source code and control flows through Parrot. Each of the four parts of Parrot are covered briefly here, with the features and parts of the interpreter covered in more detail afterward. Figure 5-1. Parrot's flow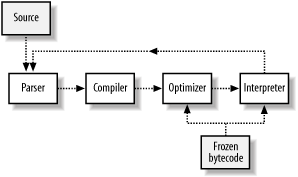 The flow starts with source code, which is passed into the parser module. The parser processes that source into a form that the compiler module can handle. The compiler module takes the processed source and emits bytecode, which Parrot can directly execute. That bytecode is passed into the optimizer module, which processes the bytecode and produces bytecode that is hopefully faster than what the compiler emitted. Finally, the bytecode is handed off to the interpreter module, which interprets the bytecode. Since compilation and execution are so tightly woven in Perl, the control may well end up back at the parser to parse more code. Parrot's compiler module also has the capability to freeze bytecode to disk and read that frozen bytecode back again, bypassing the parser and compilation phases entirely. The bytecode can be directly executed, or handed to the optimizer to work on before execution. This may happen if you've loaded in a precompiled library and want Parrot to optimize the combination of your code and the library code. The bytecode loader is interesting in its own right, and also warrants a small section. 5.2.1 ParserThe parser module is responsible for taking source code in and turning it into an Abstract Syntax Tree (AST). An AST is a digested form of the program, one that's much more amenable to manipulation. In some systems this task is split into two partsthe lexing and the parsingbut since the tasks are so closely bound, Parrot combines them into a single module. Lexing (or tokenizing) turns a stream of characters into a stream of tokens. It doesn't assign any meaning to those tokensthat's the job of the parserbut it is smart enough to see that $a = 1 + 2; is composed of 6 tokens ($, a, =, 1, +, and 2). Parsing is the task of taking the tokens that the lexer has found and assigning some meaning to them. Sometimes the parser emits executable code of a sort, when the parsed output can be directly executed. Parsing can be a chore, as anyone who's done it before knows. In some cases it can be downright maddeningPerl 5's parser has over ten thousand lines of C code. Utility programs such as lex and yacc are often used to automate the generation of parser code. Perl 5 itself uses a yacc-processed grammar to handle some of the task of parsing Perl code.[1]
Rather than going with a custom-built parser for each language, Parrot provides a general-purpose parser built on top of Perl 6's regular expression engine, with hooks for calling out to special-purpose code where necessary. Perl 6 grammar rules are designed to be powerful enough to handle parsing Perl, so it made good sense to leverage the engine as a general-purpose parser. Parrot provides some utility code to transform a yacc grammar into a Perl 6 grammar, so languages that already use yacc can be moved over to Parrot's parser with a minimum amount of fuss. This allows you to use a yacc grammar instead of a Perl 6 grammar to describe the language being parsed, both because many languages already have their grammars described with yacc and because a yacc grammar is sometimes a more appropriate way to describe things. Parrot does support independent parsers for cases where the Perl 6 regex engine isn't the appropriate choice. A language might already have an existing parser available, or different techniques might be in order. The Perl 5 parsing engine may get embedded this way, as it's easier to embed a quirky existing parser than it is to recreate all the quirks in a new parser. 5.2.2 CompilerThe compiler module takes the AST that the parser generates and turns it into code that the interpreter engine can execute. This translation is very straightforward. It involves little more than flattening the AST and running the flattened tree though a series of substitutions. The compiler is the least interesting part of Parrot. It transforms one machine representation of your programthe AST that the parser generatedinto another machine representation of your programthe bytecode that the interpreter needs. It's little more than a simple, rule-based filter module, albeit one that's necessary for Parrot to understand your source code. 5.2.3 OptimizerThe optimizer module takes the AST that the parser generated and the bytecode that the compiler generated, and transforms the bytecode to make it run faster. Optimizing code for dynamic languages such as Perl, Python, and Ruby is an interesting task. The languages are so dynamic that the optimizer can't be sure how a program will actually run. For example, the code: $a = 0;
for (1..10000);
$a++;
}
looks straightforward enough. The variable $a starts at 0, gets incremented ten thousand times, and has an end value of 10000. A standard optimizer would turn that code into the single line: $a = 10000; and remove the loop entirely. Unfortunately, that's not necessarily appropriate for Perl. $a could easily be tied, perhaps representing the position of some external hardware. If incrementing the variable ten thousand times smoothly moves a stepper motor from 0 to 10000 in increments of one, just assigning a value of 10000 to the variable might whip the motor forward in one step, damaging the hardware. A tied variable might also keep track of the number of times it has been accessed or modified. Either way, optimizing the loop away changes the semantics of the program in ways the original programmer didn't want. Because of the potential for active or tied data, especially for languages as dynamically typed as Perl, optimizing is a non-trivial task. Other languages, such as C or Pascal, are more statically typed and lack active data, so an aggressive optimizer is in order for them. Breaking out the optimizer into a separate module allows us to add in optimizations piecemeal without affecting the compiler. There's a lot of exciting work going into the problem of optimizing dynamic languages, and we fully expect to take advantage of it where we can. Optimization is potentially an expensive operation, another good reason to have it in a separate module. Spending ten seconds optimizing a program that will run in five seconds is a huge waste of time when using Perl's traditional compile-and-go modeloptimizing the code will make the program run slower. On the other hand, spending ten seconds to optimize a program makes sense if you save the optimized version to disk and use it over and over again. Even if you save only one second per program run, it doesn't take long for the ten-second optimization time to pay off. The default is to optimize heavily when freezing bytecode to disk and lightly when running directly, but this can be changed with a command-line switch. Perl 5, Python, and Ruby all lack a robust optimizer (outside their regular expression engines), so any optimizations we add will increase their performance. This, we feel, is a good thing. 5.2.4 InterpreterThe interpreter module is the part of the engine that executes the generated bytecode. Calling it an interpreter is something of a misnomer, since Parrot's core includes both a traditional bytecode interpreter module as well as a high-performance JIT engine, but you can consider that an implementation detail. All the interesting things happen inside the interpreter, and the remainder of the chapter is dedicated to the interpreter and the functions it provides. It's not out of line to consider the interpreter as the real core of Parrot, and to consider the parser, compiler, and optimizer as utility modules whose ultimate purpose is to feed bytecode to the interpreter. 5.2.5 Bytecode LoaderThe bytecode loader isn't part of our block diagram, but it is interesting enough to warrant brief coverage. The bytecode loader handles loading in bytecode that's been frozen to disk. The Parrot bytecode loader is clever enough to handle loading in Parrot bytecode regardless of the sort of system that it was saved on, so we have cross-system portability. You can generate bytecode on a 32-bit x86 system and load it up on a 64-bit Alpha or SPARC system without any problems. The bytecode loading system also has a heuristic engine built into it, so it can identify the bytecode format it's reading. This means Parrot can not only tell what sort of system Parrot bytecode was generated on so it can properly process it, but also allows it to identify bytecode generated for other bytecode driven systems, such as .NET, the JVM, and the Z-machine. Together with Parrot's loadable opcode library system (something we'll talk about later), this gives Parrot the capability to load in foreign bytecode formats and transform them into something Parrot can execute. With a sophisticated enough loader, Parrot can load and execute Java and .NET bytecode and present Java and .NET library code to languages that generate native Parrot bytecode. This is something of a happy accident. The original purpose of the architecture was to allow Parrot to load and execute Z-machine bytecode,[2] but happy accidents are the best kind.
|
|
|
|