Structure of the Data DirectoryThe MySQL data directory contains all the databases and tables managed by the server. In general, these are organized into a tree structure that is implemented in straightforward fashion by taking advantage of the hierarchical structure of the Unix or Windows filesystems:
The exception to this hierarchical implementation of databases and tables as directories and files is that the InnoDB storage engine can store all InnoDB tables from all databases within a single common tablespace. This tablespace is implemented using one or more large files that are treated as a single unified data structure within which tables and indexes are represented. The InnoDB tablespace files are stored in the data directory by default. The data directory also may contain other files:
How the MySQL Server Provides Access to DataWhen MySQL is used in the usual client/server setup, all databases under the data directory are managed by a single entity, the MySQL server mysqld. Client programs never manipulate data directly. Instead, the server provides the sole point of contact through which databases are accessed, acting as the intermediary between client programs and the data they want to use. Figure 10.1 illustrates this architecture. Figure 10.1. How the MySQL server controls access to the data directory.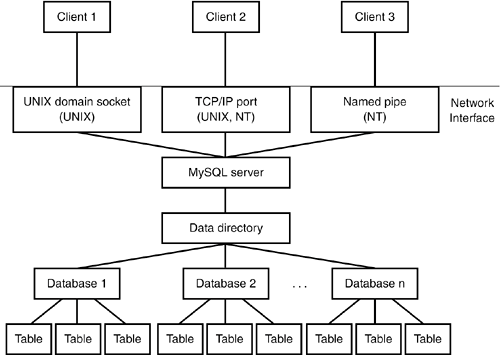 When the server starts, it opens any log files that you request it to maintain, and then presents a network interface to the data directory by listening for various types of network connections. (Details of how the server listens for connections are presented in Chapter 11, "General MySQL Administration.") To access data, a client program establishes a connection to the server, and then communicates requests as SQL queries to perform the desired operations such as creating a table, selecting records, or updating records. The server performs each operation and sends back the result to the client. The server is multi-threaded and can service multiple simultaneous client connections. However, because update operations are performed one at a time, the server in effect serializes requests so that two clients can never change a given record at exactly the same time. If you're running an application that uses the embedded server, a slightly different architecture applies, because there is only one "client"; that is, the application into which the server is linked. In this case, the server listens to an internal communication channel rather than to network interfaces. Nevertheless, it's still the embedded server part of the application that manages access to the data directory, and it's still necessary to coordinate query activity arriving over multiple connections if the application happens to open several connections to its embedded server. Under normal conditions, having the server act as the sole arbiter of database access provides assurance against the kinds of corruption that can result from multiple processes accessing the database tables at the same time. Nevertheless, administrators should be aware that there are times when the server does not have exclusive control of the data directory:
How MySQL Represents Databases in the FilesystemEach database managed by the MySQL server has its own database directory. Database directories exist as subdirectories of the data directory, each with the same name as the database it represents. For example, a database mydb corresponds to the database directory DATADIR/mydb on Unix, or DATADIR\mydb on Windows. SHOW DATABASES is essentially nothing more than a list of the names of the directories located within the data directory. Some database systems keep a master table that lists all the databases maintained, but there is no such construct in MySQL. CREATE DATABASE db_name creates a directory named db_name under the data directory to act as the database directory. As of MySQL 4.1, it also creates a db.opt file that lists the database default character set and collation. Under Unix, the database directory is owned by and accessible only to the login account that is used for running the server. This means that, except for creating the db.opt file, the CREATE DATABASE operation is equivalent to executing the following set of filesystem-level commands from the shell on the server host while logged in under that account: % cd DATADIR % mkdir db_name % chmod u=rwx,go-rwx db_name DROP DATABASE statement is implemented nearly as simply. DROP DATABASE db_name removes the db_name directory in the data directory, along with any table files contained within it. This is almost the same as executing the following commands on Unix: % cd DATADIR % rm -rf db_name Or these commands on Windows: C:\> cd DATADIR C:\> del /S db_name The differences between a DROP DATABASE statement and the filesystem-level shell commands are as follows:
How MySQL Represents Tables in the FilesystemMySQL supports several storage engines: ISAM, MyISAM, MERGE, BDB, InnoDB, MEMORY and FEDERATED. (There are also other storage engines known as EXAMPLE, ARCHIVE, and CSV, which are not covered here. For information about these three engines, see "Other Storage Engines," in Chapter 2, "MySQL SQL Syntax and Use.") Every table in MySQL is represented on disk by at least one file, which is the .frm file that contains a description of the table's structure or format. For most storage engines, there are also other files that contain the data rows and index information. The names of these files vary according to the storage engine, as outlined in the following discussion. The descriptions here focus primarily on the characteristics of the storage engines as they store files on disk. For information about how these engines differ in features and behavior, see "Storage Engine Characteristics," in Chapter 2. ISAM TablesThe ISAM engine was the original storage engine in MySQL. MySQL represents each ISAM table by three files in the database directory of the database that contains the table. The files all have a basename that is the same as the table name, and an extension that indicates the purpose of the file. For example, ISAM represents a table named mytbl by three files:
ISAM was superseded by the MyISAM storage engine some years ago and now has been rendered pretty much extinct. I don't say much about it in this book, except for purposes of comparison with other storage engines. MyISAM TablesMySQL 3.23 introduced the MyISAM storage engine as the successor to the ISAM engine. As for ISAM tables, MyISAM tables consist of three files. Within a database directory, MyISAM represents a table named mytbl by three files:
MERGE TablesA MERGE table is a logical construct. It represents a collection of identically structured MyISAM tables that are treated for query purposes as a single larger table. Within a database directory, a MERGE table named mytbl is represented by two files:
One implication of this representation is that it's possible to change the definition of a MERGE table by flushing the table cache with FLUSH TABLES and then directly editing the .MRG file to change the list of MyISAM tables named there. (I'm not sure I'd recommend actually doing this, though.) BDB TablesThe BDB storage engine represents each table by two files. Within a database directory, a table named mytbl has these two files:
InnoDB TablesThe preceding storage engines all represent tables using files that each are uniquely associated with a single table. InnoDB tables are handled in a somewhat different way. As for other storage engines, one file that corresponds directly to a given InnoDB table is the .frm table format file, which is located in the directory for the database to which the table belongs. However, InnoDB represents table contents using tablespaces, of which there are two types:
The shared tablespace is used for another purpose, too. InnoDB maintains an internal data dictionary that contains information about each of its tables. This dictionary is stored in the shared tablespace, which therefore is necessary even if you are using individual tablespaces. MEMORY TablesMEMORY tables are in-memory tables. Like other table types, a MEMORY table has an .frm file that describes its format. Otherwise, the table is not represented in the filesystem at all because the server stores a MEMORY table's data and indexes in memory rather than on disk. When the server shuts down, the contents of a MEMORY table are lost. When the server restarts, the table still exists (because the .frm file still exists), but it is empty. Before MySQL 4.1, the MEMORY storage engine was called the HEAP engine. MEMORY has become the preferred term, although HEAP still is recognized as a synonym. FEDERATED TablesA FEDERATED table is a table that points to a remote table on another MySQL server. That is, records are not stored locally, but retrieved from the remote table as necessary. Because of this, no data or indexes are stored locally. The only local file is the .frm file in the database directory that describes the table format. How SQL Statements Map onto Table File OperationsEvery storage engine uses an .frm file to store the table format (definition), so the output from SHOW TABLES FROM db_name is the same as a listing of the basenames of the .frm files in the database directory for db_name. Some database systems maintain a registry that lists all tables contained in a database. In MySQL, the closest thing to this is that the InnoDB storage engine maintains a data dictionary in the shared tablespace that lists all InnoDB tables. To create a table of any of the types supported by MySQL, you issue a CREATE TABLE statement that defines the table's structure, and that includes an ENGINE = engine_name clause to indicate which storage engine you want to use. If you omit the ENGINE clause, MySQL uses the default storage engine, which typically is MyISAM. The server creates an .frm file for the new table that contains the internal encoding of its definition, and then tells the appropriate storage engine to create any other files that are associated with the table. For example, MyISAM creates .MYD and .MYI data and index files, and BDB creates a .db data/index file. For InnoDB tables, the storage engine creates a data dictionary entry and initializes data and index information for the table within the appropriate InnoDB tablespace. Under Unix, the ownership and mode of any files created to represent the table are set to allow access only to the account that is used to run the server. When you issue an ALTER TABLE statement, the server re-encodes the table's .frm file to reflect the structural change indicated by the statement and modifies the contents of any data and index files likewise. This happens for CREATE INDEX and DROP INDEX as well because they are handled by the server as equivalent ALTER TABLE statements. If the ALTER TABLE statement changes the table's storage engine, the table contents are transferred to the new engine, which rewrites the contents using the appropriate type of files that the engine uses to represent tables. DROP TABLE is implemented by removing the files that represent the table. If you drop an InnoDB table, the InnoDB storage engine also updates its data dictionary and marks as free any space associated with the table in the InnoDB shared tablespace. For some storage engines, you can remove a table manually by removing the files in the database directory to which the table corresponds. For example, if mydb is the current database and mytbl is an ISAM, MyISAM, BDB, or MERGE table, DROP TABLE mytbl is roughly equivalent to the following commands on Unix: % cd DATADIR % rm -f mydb/mytbl.* Or to these commands on Windows: C:\> cd DATADIR C:\> del mydb\mytbl.* For an InnoDB or MEMORY table, some parts of the table are not represented within the filesystem in discrete files, so DROP TABLE does not have a filesystem command equivalent. For example, an InnoDB table that is stored in the shared tablespace is always uniquely associated with an .frm file, but removing that file does not properly drop the table. The InnoDB data dictionary must be updated by InnoDB itself, and removing the .frm file leaves the table data and indexes "stranded" within the shared tablespace. If the InnoDB table has an individual tablespace, it is represented in the database directory by the .frm file and its own .ibd file. However, it is still not correct to "drop" the table by removing those files because that does not give InnoDB a change to update the data dictionary. It is necessary to use DROP TABLE so that InnoDB can remove the files and update the data dictionary. Operating System Constraints on Database and Table NamingMySQL has general rules for database and table names. The rules are listed in detail in Chapter 2, "MySQL SQL Syntax and Use," but may be summarized briefly as follows:
The rules just listed do not form a complete list of constraints on identifiers. Names of databases and tables correspond to names of directories and files, so the operating system on which a server runs may impose additional constraints that stem from filesystem naming conventions:
One way to deal with the issue of case sensitivity is to always name your databases and tables with a given lettercase. Another is to run the server with the lower_case_table_names system variable set to 1, which has two effects:
The result of these actions is that names uniformly are treated as not case sensitive, regardless of the filesystem case sensitivity. This makes it easier to move databases and tables between systems. However, if you plan to use this strategy, you should configure the server to set the lower_case_table_names variable before you start creating databases or tables, not after. If you set the variable after having already created databases or tables that have names that include uppercase characters, the setting will not have the desired effect because you will already have names stored on disk that are not entirely lowercase. To avoid this problem, rename any tables that have names containing uppercase characters to names that are entirely lowercase before setting lower_case_table_names. (To rename a table, use ALTER TABLE or RENAME TABLE.) If you have a lot of tables that need to be renamed, or databases that have names containing uppercase characters, it is easier to dump the databases and then recreate them after setting lower_case_table_names:
lower_case_table_names has several possible values. For more information, see Appendix D, "System, Status, and User Variable Reference." Factors That Affect Maximum Table SizeTable sizes in MySQL are bounded, but sizes are limited by a combination of factors, so it is not always a simple matter to determine precisely what the bounds are. These factors affect table size:
To determine the actual table size you can achieve, you must consider all applicable factors. The effective maximum table size likely will be determined by the smallest of those factors. Suppose that you want to create a MyISAM table. MySQL will allow the data and index files to reach 4GB each, using the default data pointer size. But if your operating system imposes a size limit on files of 2GB, that will be the effective limit for the table files. On the other hand, if your system supports large files that can be bigger than 4GB, the determining factor on table size then will be a MySQL factor, namely the internal data pointer size. This is a factor that you can control. With respect to InnoDB tables that are stored in the shared tablespace, a single InnoDB table can grow as large as that tablespace and the tablespace can span multiple files to become quite large. But if, as is more likely, you have many InnoDB tables, they all share the same space and thus each is constrained in size not only by the size of the tablespace, but also by how much of the tablespace is allocated to other tables. Any individual InnoDB table can grow as long as the tablespace is not full. Conversely, when the tablespace fills up, no InnoDB table can grow any larger until you add another component to the tablespace to make it bigger. (You can make the last tablespace component auto-extending, so that it will grow as long as it does not exceed the file-size limit of your system and disk space is available. See Chapter 11 for details on tablespace configuration.) Implications of Data Directory Structure for System PerformanceThe structure of the MySQL data directory is easy to understand because it uses the hierarchical structure of the filesystem in such a natural way. At the same time, this structure has certain performance implications, particularly regarding operations that open the files that represent database tables. One consequence of the data directory structure is that, for storage engines that represent individual tables each with their own files, each open table can require a file descriptor. If a table is represented by multiple files, opening the table requires multiple file descriptors, not just one. The server caches descriptors intelligently, but a busy server can easily use up lots of them while servicing many simultaneous client connections or executing complex queries that reference several tables. This can be a problem, because file descriptors are a scarce resource on many systems, particularly those that set the default per-process descriptor limit fairly low. An operating system that imposes a low limit and makes no provision for allowing it to be increased would not make a good choice for running a high-activity MySQL server. Another effect of representing each table by its own files is that table-opening time increases with the number of tables. Operations that open tables map onto the file-opening operations provided by the operating system, and as such are bound by the efficiency of the system's directory-lookup routines. Normally this isn't much of an issue, but it is something to consider if you'll need large numbers of tables in a database. For example, a MyISAM table is represented by three files. If you want to have 10,000 MyISAM tables, your database directory will contain 30,000 files. With that many files, you may notice a slowdown due to the time taken by file-opening operations. (Solaris filesystems are subject to this problem.) If this is cause for concern, you might want to think about using a type of filesystem that is highly efficient at dealing with large numbers of files. For example, ReiserFS exhibits good performance even with large numbers of small files. If it is not possible to choose a different filesystem, it may be necessary to reconsider the structure of your tables in relation to the needs of your applications and reorganize your tables accordingly. Ask whether you really require so many tables; sometimes applications multiply tables needlessly. An application that creates a separate table per user results in many tables, all of which have identical structures. If you wanted to combine the tables into a single table, you might be able to do so by adding another column identifying the user to which each row applies. If this significantly reduces the number of tables, the application's performance improves. As always in database design, you must consider whether this particular strategy is worthwhile for a given application. Reasons not to combine tables in the manner just described are as follows:
Another way to create many tables without requiring so many individual files is to use InnoDB tables and store them in the InnoDB shared tablespace. In this case, the InnoDB storage engine associates only an .frm file uniquely with each table, and stores the data and index information for all InnoDB tables together. This minimizes the number of disk files needed to represent the tables, and it also substantially reduces the number of file descriptors required for open tables. InnoDB needs only one descriptor per component file of the tablespace (which is constant during the life of the server process), and briefly a descriptor for any table that it opens while it reads the table's .frm file. MySQL Status and Log FilesIn addition to database directories, the MySQL data directory contains a number of status and log files, as summarized in Table 10.1. The default location for each file is the server's data directory, and the default name for most of them is derived using the server host name, denoted as HOSTNAME in the table. The table lists only the server's more general log and status files. Individual storage engines may create their own logs or other files.
The Process ID FileOn Unix, the MySQL server writes its process ID (PID) into the PID file when it starts, to allow itself to be found by other processes. For example, if the operating system runs the mysql.server script at system shutdown time to stop the MySQL server, that script examines the PID file to determine which process it needs to send a termination signal to. The MySQL server removes the PID file when it shuts down. If the server cannot create the PID file (for example, if you run it on read-only media such as a CD-ROM), it writes a message to the error log and continues. The PID file is not used by the embedded server. (The embedded server needs no PID file, because it is started and stopped by the application within which it is embedded.) The MySQL Log FilesMySQL can maintain a number of different log files. Most logging is optional; you use server startup options to enable just the logs you need and also to specify their names if you don't like the default names. Be aware that logs can grow quite large, so it's important to make sure they don't fill up your filesystem. You can expire the logs periodically to keep the amount of space that they use within bounds. This section briefly describes a few of the log files. For more information about the logs, the options that control the server's logging behavior, and log expiration, see "Maintaining Log Files," in Chapter 11. The error log contains a record of diagnostic information produced by the server when exceptional conditions occur. This log is useful if the server fails to start up or exits unexpectedly, because often it will contain the reason why. The general log provides general information about server operation: who is connecting from where and what statements they are issuing. The binary log contains statement information, too, but only for statements that modify database contents. It also contains information such as timestamps needed to keep slave servers synchronized when the server is a master server in a replication setup. The contents of the binary log are written in binary format as SQL statements that can be executed by providing them as input to the mysql client. The accompanying binary log index file lists which binary log files the server currently is maintaining. The binary logs are useful if you have a crash and must revert to backup files, because you can repeat the updates performed after the backup was made by feeding the logs to the server. This allows you to bring your databases up to the state they were in when the crash occurred. This procedure is described in more detail in Chapter 13. The binary logs are also used if you set up replication servers, because they serve as a record of the updates that must be transmitted from a master server to slave servers. Here is a sample of the kind of information that appears in the general log as the result of a short client session that creates a table in the test database, inserts a row into the table, and then drops the table: 040812 11:38:34 31 Connect sampadm@localhost on sampdb 040812 11:38:42 31 Query CREATE TABLE mytbl (val INT) 040812 11:38:47 31 Query INSERT INTO mytbl VALUES(1) 040812 11:38:52 31 Query DROP TABLE mytbl 040812 11:38:56 31 Quit The general log contains columns for date and time, server thread ID (connection ID), event category, and event-specific information. For any line that is missing the date and time fields, the values are the same as for the previous line that does have them. (In other words, the server logs the date and time only when they change from the previously logged date and time.) The same session appears in the binary log as follows when viewed by displaying its contents with the mysqlbinlog program. (The output is slightly reformatted to accommodate long lines.) The statements include terminating semicolons, allowing them to be given as input to the mysql program should the updates need to be repeated for a database recovery operation. Comment lines begin with '#' characters. # at 1222 #040812 11:38:42 server id 1 log_pos 1222 Query thread_id=31 exec_time=0 error_code=0 use sampdb; SET TIMESTAMP=1092328722; CREATE TABLE mytbl (val INT); # at 1287 #040812 11:38:47 server id 1 log_pos 1287 Query thread_id=31 exec_time=0 error_code=0 SET TIMESTAMP=1092328727; INSERT INTO mytbl VALUES(1); # at 1351 #040812 11:38:52 server id 1 log_pos 1351 Query thread_id=31 exec_time=0 error_code=0 SET TIMESTAMP=1092328732; DROP TABLE mytbl; It's a good idea to make sure that your log files are secure and not readable by arbitrary users, because they may contain the text of queries that include sensitive information such as passwords. For example, the following log entry displays the password for the root user; it's certainly not the kind of information you want just anyone to have access to:
040812 16:47:24 44 Query UPDATE user
SET Password=PASSWORD('secret')
WHERE user='root'
The logs are written to the data directory by default, so a good precaution for securing your logs is to secure the data directory against being accessed on the server host by login accounts other than the one used by the MySQL administrator. A detailed procedure for this is presented in Chapter 12, "MySQL and Security." |