Atomic OperationsAtomic operations provide instructions that execute atomicallywithout interruption. Just as the atom was originally thought to be an indivisible particle, atomic operators are indivisible instructions. For example, as discussed in the previous chapter, an atomic increment can read and increment a variable by one in a single indivisible and uninterruptible step. Instead of the race discussed in the previous chapter, the outcome is always similar to the following (assume i is initially seven):
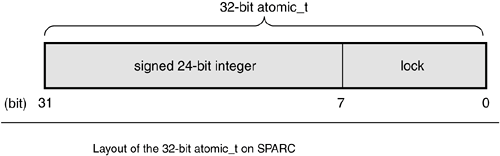
The resulting value, nine, is correct. It is never possible for the two atomic operations to occur on the same variable concurrently. Therefore, it is not possible for the increments to race. The kernel provides two sets of interfaces for atomic operationsone that operates on integers and another that operates on individual bits. These interfaces are implemented on every architecture that Linux supports. Most architectures either directly support simple atomic operations or provide an operation to lock the memory bus for a single operation (and thus ensure another operation cannot occur simultaneously). Architectures that cannot easily support primitive atomic operations, such as SPARC, somehow cope. (The only atomic instruction that is guaranteed to exist on all SPARC machines is ldstub.) Atomic Integer OperationsThe atomic integer methods operate on a special data type, atomic_t. This special type is used, as opposed to having the functions work directly on the C int type, for a couple of reasons. First, having the atomic functions accept only the atomic_t type ensures that the atomic operations are used only with these special types. Likewise, it also ensures that the data types are not passed to any other nonatomic functions. Indeed, what good would atomic operations be if they were not consistently used on the data? Next, the use of atomic_t ensures the compiler does not (erroneously but cleverly) optimize access to the valueit is important the atomic operations receive the correct memory address and not an alias. Finally, use of atomic_t can hide any architecture-specific differences in its implementation. Despite being an integer, and thus 32 bits on all of the machines that Linux supports, developers and their code once had to assume that an atomic_t was no larger than 24 bits in size. The SPARC port in Linux has an odd implementation of atomic operations: A lock was embedded in the lower 8 bits of the 32-bit int (it looked like Figure 9.1). The lock was used to protect concurrent access to the atomic type because the SPARC architecture lacks appropriate support at the instruction level. Consequently, only 24 usable bits were available on SPARC machines. Although code that assumed that the full 32-bit range existed would work on other machines, it would have failed in strange and subtle ways on SPARC machinesand that is just rude. Recently, clever hacks have allowed SPARC to provide a fully usable 32-bit atomic_t, and this limitation is no more. The old 24-bit implementation is still used by some internal SPARC code, however, and lives in SPARC's <asm/atomic.h>. Figure 9.1. Old layout of the 32-bit atomic_t on SPARC.
The declarations needed to use the atomic integer operations are in <asm/atomic.h>. Some architectures provide additional methods that are unique to that architecture, but all architectures provide at least a minimum set of operations that are used throughout the kernel. When you write kernel code, you can ensure that these operations are correctly implemented on all architectures. Defining an atomic_t is done in the usual manner. Optionally, you can set it to an initial value: atomic_t v; /* define v */ atomic_t u = ATOMIC_INIT(0); /* define u and initialize it to zero */ Operations are all simple: atomic_set(&v, 4); /* v = 4 (atomically) */ atomic_add(2, &v); /* v = v + 2 = 6 (atomically) */ atomic_inc(&v); /* v = v + 1 = 7 (atomically) */ If you ever need to convert an atomic_t to an int, use atomic_read():
printk("%d\n", atomic_read(&v)); /* will print "7" */
A common use of the atomic integer operations is to implement counters. Protecting a sole counter with a complex locking scheme is silly, so instead developers use atomic_inc() and atomic_dec(), which are much lighter in weight. Another use of the atomic integer operators is atomically performing an operation and testing the result. A common example is the atomic decrement and test: int atomic_dec_and_test(atomic_t *v) This function decrements by one the given atomic value. If the result is zero, it returns true; otherwise, it returns false. A full listing of the standard atomic integer operations (those found on all architectures) is in Table 9.1. All the operations implemented on a specific architecture can be found in <asm/atomic.h>.
The atomic operations are typically implemented as inline functions with inline assembly (apparently, kernel developers like inlines). In the case where a specific function is inherently atomic, the given function is usually just a macro. For example, on most sane architectures, a word-sized read is always atomic. That is, a read of a single word cannot complete in the middle of a write to that word. The read will always return the word in a consistent state, either before or after the write completes, but never in the middle. Consequently, atomic_read() is usually just a macro returning the integer value of the atomic_t. In your code, it is usually preferred to choose atomic operations over more complicated locking mechanisms. On most architectures, one or two atomic operations incur less overhead and less cache-line thrashing than a more complicated synchronization method. As with any performance-sensitive code, however, testing multiple approaches is always smart. Atomic Bitwise OperationsIn addition to atomic integer operations, the kernel also provides a family of functions that operate at the bit level. Not surprisingly, they are architecture specific and defined in <asm/bitops.h>. What may be surprising is that the bitwise functions operate on generic memory addresses. The arguments are a pointer and a bit number. Bit zero is the least significant bit of the given address. On 32-bit machines, bit 31 is the most significant bit and bit 32 is the least significant bit of the following word. There are no limitations on the bit number supplied, although most uses of the functions provide a word and, consequently, a bit number between 0 and 31 (or 63, on 64-bit machines). Because the functions operate on a generic pointer, there is no equivalent of the atomic integer's atomic_t type. Instead, you can work with a pointer to whatever data you desire. Consider an example:
unsigned long word = 0;
set_bit(0, &word); /* bit zero is now set (atomically) */
set_bit(1, &word); /* bit one is now set (atomically) */
printk("%ul\n", word); /* will print "3" */
clear_bit(1, &word); /* bit one is now unset (atomically) */
change_bit(0, &word); /* bit zero is flipped; now it is unset (atomically) */
/* atomically sets bit zero and returns the previous value (zero) */
if (test_and_set_bit(0, &word)) {
/* never true */
}
/* the following is legal; you can mix atomic bit instructions with normal C */
word = 7;
A listing of the standard atomic bit operations is in Table 9.2.
Conveniently, nonatomic versions of all the bitwise functions are also provided. They behave identically to their atomic siblings, except they do not guarantee atomicity and their names are prefixed with double underscores. For example, the nonatomic form of test_bit() is __test_bit(). If you do not require atomicity (say, for example, because a lock already protects your data), these variants of the bitwise functions might be faster. The kernel also provides routines to find the first set (or unset) bit starting at a given address: int find_first_bit(unsigned long *addr, unsigned int size) int find_first_zero_bit(unsigned long *addr, unsigned int size) Both functions take a pointer as their first argument and the number of bits in total to search as their second. They return the bit number of the first set or first unset bit, respectively. If your code is searching only a word, the routines __ffs() and ffz(), which take a single parameter of the word in which to search, are optimal. Unlike the atomic integer operations, code typically has no choice whether to use the bitwise operationsthey are the only portable way to set a specific bit. The only question is whether to use the atomic or nonatomic variants. If your code is inherently safe from race conditions, you can use the nonatomic versions, which might be faster depending on the architecture. |