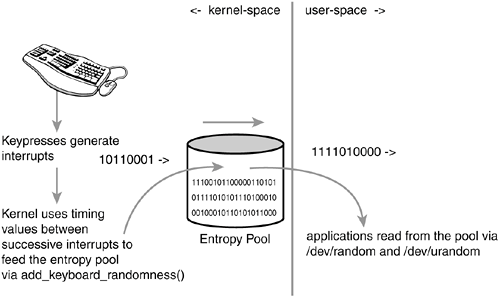
Design and ImplementationComputers are predictable devices. Indeed, it is hard to find randomness in a system whose behavior is entirely programmed. The environment of the machine, however, is full of noise that is accessible and non-deterministic. Such sources include the timing of various hardware devices and user interaction. For example, the time between key presses, the movement of the mouse, the timingparticularly the low-order bits of such timingbetween certain interrupts, and the time taken to complete a block I/O request are all both non-deterministic and not measurable by an outside attacker. Randomness from these values is taken and fed into the entropy pool. The pool grows to become a random and unpredictable mixture of noise. As the values are added to the pool, an estimate of the randomness is calculated and a tally is kept. This allows the kernel to keep track of the entropy in the pool. Figure B.1 is a diagram of the flow of entropy into and out of the pool. Figure B.1. The flow of entropy into and out of the kernel entropy pool.
The kernel provides a set of interfaces to allow access to the entropy pool, both from within the kernel and from user-space. When the interfaces are accessed, the kernel first takes the SHA hash of the pool. SHA (Secure Hash Algorithm) is a message digest algorithm developed by the National Security Agency (NSA) and made a U.S. federal standard by NIST (via FIPS 186). A message digest is an algorithm that takes a variable-sized input (small or large) and outputs a fixed-size hash value (typically 128 or 160 bits) that is a "digest" of the original input. From the outputted hash value, the input cannot be reconstructed. Further, trivial manipulations to the input (for example, changing a single character) result in a radically different hash value. Message digest algorithms have various uses, including data verification and fingerprinting. Other message digest algorithms include MD4 and MD5. The SHA hash, not the raw contents of the pool, is returned to the user; the contents of the entropy pool are never directly accessible. It is assumed impossible to derive any information about the state of the pool from the SHA hash. Therefore, knowing some values from the pool does not lend any knowledge to past or future values. Nonetheless, the kernel can use the entropy estimate to refuse to return data if the pool has zero entropy. As entropy is read from the pool, the entropy estimate is decreased in response to how much information is now known about the pool. When the estimate reaches zero, the kernel can still return random numbers. Theoretically, however, an attacker is then capable of inferring future output given prior output. This would require that the attacker have nearly all the prior outputs from the entropy pool and that the attacker successfully perform cryptanalysis on SHA. Because SHA is believed to be secure, this possibility is not feasible. To high-security cryptography users who accept no risk, however, the entropy estimate ensures the strength of the random numbers. To the vast majority of users this extra assurance is not needed. The Dilemma of System StartupWhen the kernel first boots, it completes a series of actions that are almost entirely predictable. Consequently, an attacker is able to infer much about the state of the entropy pool at boot. Worse, each boot is largely similar to the next and the pool would initialize to largely the same contents on each boot. This reduces the accuracy of the entropy estimate, which has no way of knowing that the entropy contributed during the boot sequence is less predictable than entropy contributed at other times. To offset this problem, most Linux systems save some information from the entropy pool across system shutdowns. They do this by saving the contents of the entropy pool on each shutdown. When the system boots, the data is read and fed into /dev/urandom. This effectively loads the previous contents of the pool into the current pool, without increasing the entropy estimate. Therefore, an attacker cannot predict the state of the entropy pool without knowledge of both the current state of the system and the previous state of the system. |