| only for RuBoard - do not distribute or recompile |
A client request method is a command or request that a web client issues to a server. You can think of the method as the declaration of the client's intentions. There are exceptions, of course, but here are some generalizations:
You can think of a GET request as meaning that you just want to retrieve a resource on the server. This resource could be the contents of a static file or invoke a program that generates data.
A HEAD request means that you just want some information about the document, but don't need the document itself.
A POST request says that you're providing some information of your own (generally used for fill-in forms). This typically changes the state of the server in some way. For example, it could create a record in a database.
PUT is used to provide a new or replacement document to be stored on the server.
DELETE is used to remove a document on the server.
TRACE asks that proxies declare themselves in the headers, so the client can learn the path that the document took (and thus determine where something might have been garbled or lost). This is used for protocol debugging purposes.
OPTIONS is used when the client wants to know what other methods can be used for that document (or for the server at large).
CONNECT is used when a client needs to talk to a HTTPS server through a proxy server.
Other HTTP methods that you may see (LINK, UNLINK, and PATCH) are less clearly defined.
The GET method requests a document from a specific location on the server. This is the main method used for document retrieval. The response to a GET request can be generated by the server in many ways. For example, the response could come from:
A file accessible by the web server
The output of a CGI script or server extension language like NSAPI, ISAPI, Apache modules, Java Server Pages, Active Server Pages, etc.
The result of a server computation, for instance real-time decompression of online files
Information obtained from a hardware device, such as a video camera
After the client uses the GET method in its request, the server responds with a status line, headers, and data requested by the client. If the server cannot process the request, due to an error or lack of authorization, the server usually sends an explanation in the entity-body of the response.
For example:
GET / HTTP/1.1 Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */* Accept-Language: en-us Accept-Encoding: gzip, deflate User-Agent: Mozilla/4.0 (compatible; MSIE 5.01; Windows NT) Host: hypothetical.ora.com Connection: Keep-Alive
The server responds with:
HTTP/1.1 200 OK Date: Mon, 06 Dec 1999 20:54:26 GMT Server: Apache/1.3.6 (Unix) Last-Modified: Fri, 04 Oct 1996 14:06:11 GMT ETag: "2f5cd-964-381e1bd6" Accept-Ranges: bytes Content-length: 327 Connection: close Content-Type: text/html (body of document here)
The HEAD method is functionally like GET, except that the server replies with a response line and headers, but no entity-body. The headers returned by the server with the HEAD method should be exactly the same as the headers returned with a GET request. This method is often used by web clients to verify the document's existence or properties (like Content-length or Content-type), but the client has no intention of retrieving the document in the transaction. Many applications exist for the HEAD method, which make it possible to retrieve:
Modification time of a document for caching purposes
Size of the document, to do page layout, estimate arrival time, or skip the document and retrieve a smaller version of the document
Type of the document, to allow the client to examine only documents of a certain type
Type of server, to allow customized server queries
It is important to note that most of the header information provided by a server is optional, and may not be given by all servers.
For example:
GET / HTTP/1.1 Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */* Accept-Language: en-us Accept-Encoding: gzip, deflate User-Agent: Mozilla/4.0 (compatible; MSIE 5.01; Windows NT) Host: hypothetical.ora.com Connection: Keep-Alive
The server responds with:
HTTP/1.1 200 OK Date: Mon, 06 Dec 1999 20:54:26 GMT Server: Apache/1.3.6 (Unix) Last-Modified: Fri, 04 Oct 1996 14:06:11 GMT ETag: "2f5cd-964-381e1bd6" Accept-Ranges: bytes Content-length: 327 Connection: close Content-type: text/html
Note the server does not return any data after the headers.
The POST method allows the client to specify data to be sent to some data-handling program that the server can access. It can be used for many applications. For example, POST could be used to provide input for:
CGI programs
Gateways to network services, like an NNTP server
Command-line interface programs
Annotation of documents on the server
Database operations
In practice, POST is used with CGI programs that happen to interface with other resources like network services and command-line programs. In the future, POST may be directly interfaced with a wider variety of server resources.
In a POST request, the data sent to the server is in the entity-body of the client's request. After the server processes the POST request and headers, it may pass the entity-body to another program (specified by the URL) for processing. In some cases, a server's custom API may handle the data, instead of a program external to the server.
POST requests should be accompanied by a Content-type header, describing the format of the client's entity-body. The most commonly used format with POST is the URL-encoding scheme used for CGI applications. It allows form data to be translated into a list of variables and values. Browsers that support forms send the data in URL-encoded format. For example, given the HTML form of:
<title>Create New Account</title> <center><hr><h1>Account Creation Form</h1><hr></center> <form method="post" action="/cgi-bin/create.pl"> <pre> <b> Enter user name: <INPUT NAME="user" MAXLENGTH="20" SIZE="20"> Password: <INPUT NAME="pass1" TYPE="password" MAXLENGTH="20" SIZE="20"> (Type it again to verify) <INPUT NAME="pass2" TYPE="password" MAXLENGTH="20" SIZE="20"> </b> </pre> <INPUT TYPE="submit" VALUE="Create account"> <input type="reset" value="Start over"> </form>
Let's insert some values and submit the form. As the username, util-tester was entered. For the password, 1234 was entered (twice). Upon submission, the client sends:
POST /cgi-bin/create.pl HTTP/1.1 Host: examples.ora.com Referer: http://examples.ora.com/create.html Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */* Content-type: application/x-www-form- urlencoded Content-length: 38 user=util-tester&pass1=1234&pass2=1234
Now the variables defined in the form have been associated with the values entered by the user. This information is then passed to the server in URL-encoded format, which is described below.
The server determines that the client used a POST method, processes the URL, executes the program associated with the URL, and pipes the client's entity-body to a program specified at the address of /cgi-bin/create.pl. The server maps this "web address" to the location of a program, usually in a designated CGI directory (in this case, /cgi-bin). The CGI program then interprets the input as CGI data, decodes the entity body, processes it, and returns a response entity-body to the client:
HTTP/1.0 200 OK Date: Sat, 20-May-95 03:25:12 GMT Server: NCSA/1.3 MIME-version: 1.0 Content-type: text/html Last-modified: Wed, 14-Mar-95 18:15:23 GMT Content-length: 95 <title>User Created</title> <h1>The util-tester account has been created </h1>
Using the POST method is not the only way that forms send information. Forms can also use the GET method, and append the URL-encoded data to the URL, following a question mark. If the <form> tag had contained the line method="get" instead of method="post", the request would have looked like this:
GET /cgi-bin/create.pl?user=util- tester&pass1=1234&pass2=1234 HTTP/1.1 Host: examples.ora.com Referer: http://examples.ora.com/create.html Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*
This is one reason that the data sent by a CGI program is in a special format: since it can be appended to the URL itself, it cannot contain special characters such as spaces, newlines, etc. For that reason, it is called URL-encoded.
The URL-encoded format, identified with a Content-type of application/x-www-form-urlencoded format by clients, is composed of a single line with variable names and values concatenated together. The variable and value are separated by an equal sign (=), and each variable/value pair is separated by an ampersand symbol (&). In the example given above, there are three variables: user, pass1, and pass2. The values (respectively) are: util-tester, 1234, and 1234. The encoding looks like this:
user=util-tester&pass1=1234&pass2=1234
When the client wants to send characters that normally have special meanings, like the ampersand and equal sign, the client replaces the characters with a percent sign (%) followed by an ASCII value in hexadecimal (base 16). This removes ambiguity when a special character is used. The only exception, however, is the space character (ASCII 32), which can be encoded as a plus sign (+) as well as %20. The preferred format is %20 instead of the plus sign.
When the server retrieves information from a form, the server passes it to a CGI program, which then decodes it from URL-encoded format to retrieve the values entered by the user.
POST isn't limited to the application/x-www-form-urlencoded content type. Consider the following HTML:
<form method="post" action="post.pl" enctype="multipart/form-data"> Enter a file to upload:<br> <input name="thefile" type="file"><br> <input name="done" type="submit"> </form>
This form allows the user to select a file and upload it to the server. Notice that the <form> tag contains an enctype attribute, specifying an encoding type of multipart/form-data instead of the default, application/x-www-form-urlencoded. This encoding type will be used by the browser as the content type when the form is submitted. As an example, suppose I create a file called hi.txt with the contents "hi there" and put it in c:/temp/. I use the HTML form to include the file and then hit the submit button. My browser sends this:
POST /cgi-bin/post.pl HTTP/1.0 Referer: http://hypothetical.ora.com/clinton/upload.html Connection: Keep-Alive User-Agent: Mozilla/3.01Gold (WinNT; U) Host: hypothetical.ora.com Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */* Content-type: multipart/form-data; boundary=-- -------------------------11512135131576 Content-Length: 313 -----------------------------11512135131576 Content-Disposition: form-data; name="done" Submit Query -----------------------------11512135131576 Content-Disposition: form-data; name="thefile"; filename="c:\temp\hi.txt" Content-Type: text/plain hi there -----------------------------11512135131576--
The entity-body of the request is a multipart Multipurpose Internet Mail Extensions (MIME) message. See RFC 1867 for more details.
When a client uses the PUT method, it requests that the included entity-body should be stored on the server at the requested URL. With HTML editors, it is possible to publish documents onto the server with a PUT method. Given an HTML editor with some sample HTML in the editor, suppose the user saves the document in C:\temp\example.html and publishes it to http://publish.ora.com/example.htm.
When the user presses the OK button, the client contacts publish.ora.com at port 80 and then sends:
PUT /example.html HTTP/1.1 Host: publish.ora.com Pragma: no-cache Connection: close User-Agent: SimplePublish/1.0 Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */* Content-type: text/html Content-Length: 182 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2//EN"> <HTML> <HEAD> <TITLE></TITLE> </HEAD> <BODY> <H2>This is a header</H2> <P>This is a simple html document.</P> </BODY> </HTML>
The server stores the client's entity-body at /example.html and then responds with:
HTTP/1.0 201 Created Date: Fri, 04 Oct 1996 14:31:51 GMT Server: HypotheticalPublish/1.0 Content-type: text/html Content-length: 30 <h1>The file was created.</h1>
In practice, a web server may request authorization from the client. Most webmasters won't allow any arbitrary client to publish documents on the server. When prompted with an "authorization denied" response code, the browser will typically ask the user to enter relevant authorization information. After receiving the information from the user, the browser retransmits the request with additional headers that describe the authorization information.
It should be noted that some publishing applications forget to include a Content-type in the PUT request. This does not conform to the HTTP specification, but workarounds in some server software may exist for it.
Since PUT creates new URLs on the server, it seems appropriate to have a mechanism to delete URLs as well. The DELETE method does what you think it would do.
A client request might read:
DELETE /images/logo22.gif HTTP/1.1 Host: hypothetical.ora.com
The server responds with a success code upon success:
HTTP/1.0 200 OK Date: Fri, 04 Oct 1996 14:31:51 GMT Server: HypotheticalPublish/1.0 Content-type: text/html Content-length: 21 <h1>URL deleted.</h1>
Needless to say, any server that supports the DELETE method is likely to request authorization before carrying through with the request.
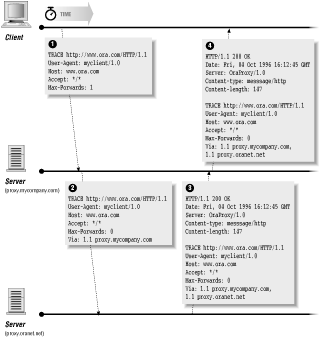
The TRACE method allows a programmer to see how the client's message is modified as it passes through a series of proxy servers. The recipient of a TRACE method echoes the HTTP request headers back to the client. When the TRACE method is used with the Max-Forwards and Via headers, a client can determine the chain of intermediate proxy servers between the original client and web server. The Max-Forwards request header specifies the number of intermediate proxy servers allowed to pass the request. Each proxy server decrements the Max-Forwards value and appends its HTTP version number and hostname to the Via header. A proxy server that receives a Max-Forwards value of returns the client's HTTP headers as an entity-body with the Content-type of message/http. This feature resembles trace-route, a UNIX program used to identify routers between two machines in an IP-based network. HTTP clients do not send an entity-body when issuing a TRACE request.
Figure 1.4 shows the progress of a TRACE request. After the client makes the request, the first proxy server receives the request, decrements the Max-Forwards value by one, adds itself to a Via header, and forwards it to the second proxy server. The second proxy server receives the request, adds itself to the Via header, and sends the request back, since Max-Forwards is now (zero).
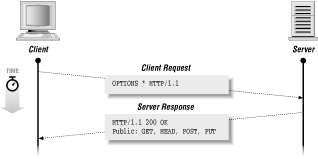
When a client request contains the OPTIONS method, it requests a list of options for a particular resource on the server. The client specifies a URL for the OPTIONS method, or an asterisk (*) to refer to the entire server. The server then responds with a list of request methods or other options that are valid for the requested resource, using the Allow header for an individual resource, or the Public header for the entire server. Figure 1.5 shows an example of the OPTIONS method in action.
When an http client wants to connect to an HTTPS server, but needs to do it through a proxy server, it issues a CONNECT to the proxy server. For example, the client connects to the proxy server and issues:
CONNECT www.onsale.com:443 HTTP/1.0 User-Agent: Mozilla/4.08 [en] (WinNT; U ;Nav)
And the server responds with:
HTTP/1.0 200 Connection established Proxy-agent: Apache/1.3.9 (Unix)
From there, all traffic is encrypted with SSL. The browser sends another HTTP message, this time inside the connection that was established with CONNECT through the proxy server. At this point, the proxy server just relays the data between the client and origin server.
| only for RuBoard - do not distribute or recompile |