7.5. Asynchronous SystemsWith connection and I/O timeouts measured in milliseconds, you can move toward keeping your page requests responding in under the magic 200 ms limit (or whatever limit you choose). The problem with this is that some services are going to take longer than a single page request to complete. Some tasks might require several minutes, while others might take a variable amount of time. Any task that doesn't have the same parallelization as your web server has the potential to block web server threads when many of the tasks are executed in tandem. Waiting for a page to load for several seconds is a bad user experience, first and foremost. The user can't distinguish the action taking a long time from the connection stalling or the service failing. If users mistake slow load times for connection stalling, then there's a good chance they'll refresh the request. If the action they're performing has limited parallelization, then the more times the action is submitted, the longer each action will take. This leads quickly to a vicious circle where the user submits the action again and again until the service fails completely. On top of the issue of a bad user experience, requests that take a long time to fulfill will collapse the rest of the system. Apache and the underlying OS will only spawn a certain amount of child processes before either turning new requests away or crashing. Neither is it just an Apache issueany resources that the request processes have opened will remain in use until the request finishes, unless you're purposefully careful about freeing them. The usual point at which you'll notice this is when your master database becomes starved of connections; many web server processes have open connections that they're not executing anything on (because they're blocking on some other service). When new processes try to access the database, they get turned away. Even though you have enough processor cycles to serve new requests, there aren't enough database connection threads available. The same goes for any other connection limited resource that you have open at the time. The solution isn't necessarily to close opened connections before calling remote services; that would cause rapid connect/disconnect cycles in the case where you needed to loop performing a remote call and a database operation (assuming your database connection layer pays a large cost for connecting and disconnecting). That said, it's good practice to close resources as soon as you've finished using themyour database might support 500 simultaneous connections, but it will use less memory and incur less context-switching overhead if you only use 20 of them. The solution is to move services to an asynchronous model. You optimize the requesting phase to respond immediately and store your request. The response phase, if one is actually needed, can come later, outside of the page request. When we talk about asynchronous services, we tend to mean services with synchronous requests and asynchronous responses. Some services won't require a response as long as we know that the request will be eventually fulfilled (or if we don't care if it is). Distributed logging systems are a good example. We send a log message to the dispatcher, which immediately returns. The dispatcher daemon might send the log message straight away. It might queue up a few hundred log messages before dispatching them. It might wait for several hours because the central log collector is down. The point is that our page request process doesn't careas long as the message made it to the dispatcher, we can ignore it. For services that do require a response, there are two easy ways of achieving this: callbacks and tickets. We'll talk about callbacks, shown in Figure 7-1, first. Figure 7-1. A callback model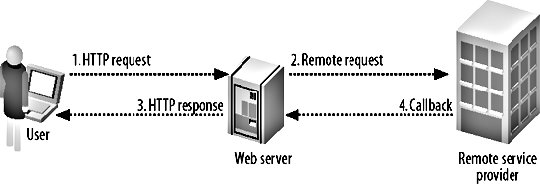 When making a request to a remote service, we can pass along a way to reach us when the request is complete, along with the details of the request itself. When we're working on a multithreaded program, callbacks are simple to achieve using regular function call semantics. Outside of a single program, things can get a little more complicated. Sockets can be useful for remote callbacks but will only work if the requesting program is going to be running when the action completesnot too useful for a page request process that'll be gone in 200 ms. Inside a trusted system, you can call back into the web application logic by having the asynchronous process execute part of the application. In this case, step 4 of the callback process would involve the remote service invoking some predetermined program, along the lines of php -q /var/webapp/async_callback.php. This can suffer from problems with process limitations at peak times, and doesn't work so well if the remote service resides on another machine. We could create a daemon running locally that gets callbacks from the remote service and executes a local script, so that the daemon can manage the parallelization of the callbacks. But wait, we already have one of those: we call it a web server! A useful callback method, and inline with our desire to not create new protocols and work for ourselves, is to have the remote service request a page from the originating web server when an action is complete. The web server takes care of the protocol and rate limiting and sends the callback request to us. If we also make step 2 of the process (making a request) use HTTP, then we don't have to invent anything newbonus! The problem with performing callbacks is that while this works well inside our data center, we have no mechanism for a web server to callback to a client. If we need to provide asynchronous services to a web client then we need to start using tickets, shown in Figure 7-2. Figure 7-2. Processing a ticket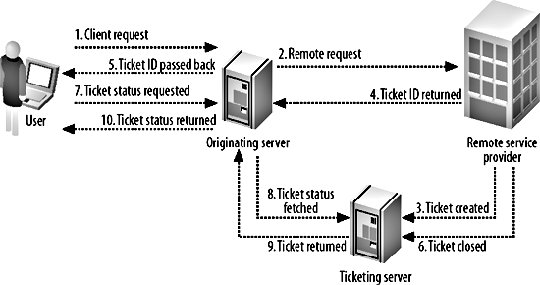 Don't be put offtickets aren't as complicated as the diagram suggests. In a ticketing system, we add a third service that keeps track of jobs in progress. When the client makes a request, the remote service creates a new ticket and returns the ticket ID to the caller. We can then use this ID to query the ticket tracker. Until the job has been completed, the ticket tracker will tell us that this job is in progress. When the remote service completes its action, it updates the ticket in the ticket tracker. The next time the client service requests the ticket status, it'll be told that it's completed. It's not all as wonderful as it may seemthere are a couple of downsides to using a ticketing system. First, you need to actually provide a ticketing server. A light ticket load can be fairly trivial for a regular database. Every read and update of the tickets can be a constant primary key lookup, so it is nice and fast. The problem occurs when you start to get a high volume for reads and writes. The higher the number of writes running through the system, the less the database server will be able to cacheif the entire working dataset rotates every minute or so, there isn't much of a window for cacheability. For really high-volume ticketing systems, it can sometimes be worth designing a component from scratch to ensure that all tickets are always kept in memory. We'll look into memory-based redundant systems in a little more detail in Chapter 9. Within Flickr, as shown in Figure 7-3, the image-processing subsystem uses both ticket and callback asynchronous systems. Figure 7-3. A hybrid asynchronous callback and ticketing system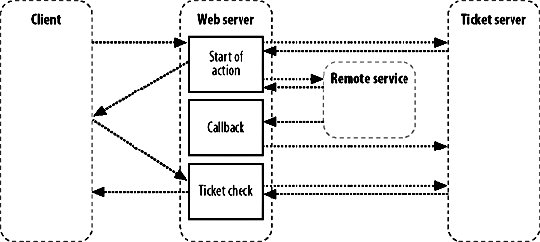 Processing images takes a few seconds per image, and at peak times time can get a queue of images to process. We use a callback system between our web servers and the image processing servers so that we can be alerted when a file has been processed and is ready for storage and indexing. We can't use a callback to alert the client that we're complete, since the web works in the other direction only. Instead, we create a ticket for the client and have the client check the ticket (by making a HTTP request) periodically until it's completed. Once the job is complete and the callback has been fired, we update the ticket status to "completed." When the client next requests ticket status, we can tell them it completed. The Flickr file storage subsystem uses a semisynchronous protocol. When storing a file, we write it to multiple locations for redundancy. The writes to primary storage are performed synchronously, since we can't display a photo until it's been written to the disk we'll be reading it from. The writes to backup storage can happen asynchronously, since we don't care when it happens, as long as it actually happens. We can make asynchronous storage requests and assume that the backup copy will be written at some point. It's important not to forget that, if you have services that your application assumes will complete requests eventually, you'll need to monitor them to check they do finally get processed. We'll talk more about monitoring in Chapter 10. |