|
|
Computing as a UtilityCurrent trends seem to be pointing toward a future where computing will be viewed as a utility, in a model similar to electrical power or cable TV. The early indications came with the development of the Application Service Provider For a better model of computing as a utility, the scenarios would look something like this:
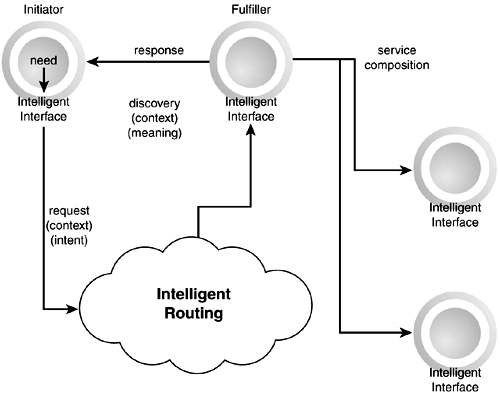
It can be argued that most of these tasks could be done by a combination of manual labor and custom applications and tools, using current technologies. Although this is true, the combination of system embedded intelligence, seamless integration of all the tasks, and lack of human involvement in the process of integration makes these scenarios remarkable. In the next sections, we will explore some of the technologies that will make this possible. Web Services Everywhere: The VisionAs the previous examples illustrate, the manifestation of the global conceptual vision of Web services is relatively simple: A need is triggered in a system, whether through human intervention or through external automated triggers. This need is translated into one or more formalized requests through some intelligent interfaces. These requests make their way into the grid/ network and are routed intelligently to other entities that can act as possible fulfillers. The requestors and potential fulfillers negotiate a set of mutually satisfactory terms and the need is serviced. This simple cycle is shown in Figure 9.1. Figure 9.1. The Web services request-response cycle.
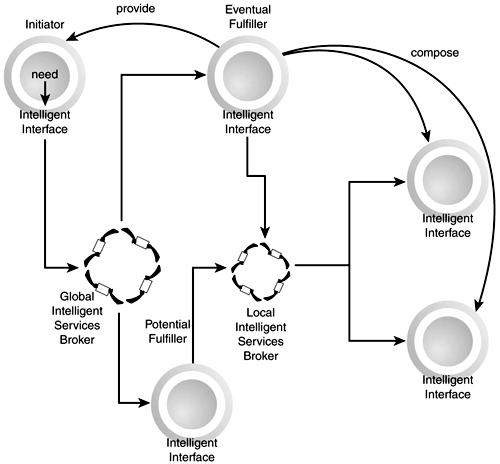
This general flow can be implemented using different architectural models, with two extremes being the ones we'll call the centralized and peer models. The Centralized ModelIn the centralized model (Figure 9.2), some relatively well-known public or private (also global or local) brokering services are central to the architecture. Entities wishing to provide services will make themselves known to these brokers, and entities seeking services will transmit their requests to the brokers. Brokers will have varying levels of intelligence built into them, allowing them to learn from experience, for example, in order to provide better matching capabilities to the incoming requests. Although the term broker implies an active role in putting requestor and provider together, with some possible benefit to the broker, we are including static services registries like UDDI (see Chapter 7) in this general category. A typical scenario would be for a requestor to discover one or more potential providers through the global broker, and maybe for one or more of these potential providers to discover and compose sub-services of their own through some private or local brokers in order to fulfill the request. Figure 9.2. The Web services centralized model.
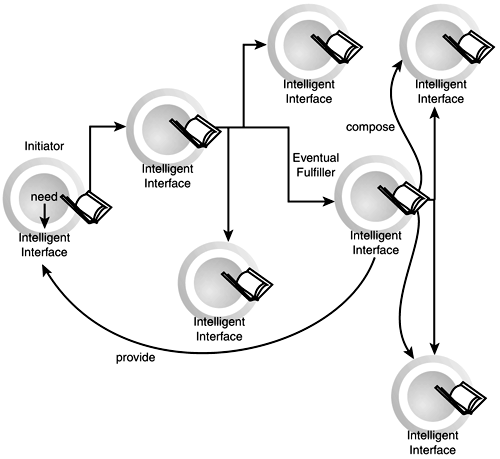
The current WSDL and UDDI technologies (discussed in Chapters 6, "Describing Web Services," and 7, "Discovering Web Services") are sufficient for design time (static) browsing, and some instances of runtime (dynamic) discovery of services. The next step in service description and discovery, however, will have to go beyond the level of syntactic Interface Definition Languages The Peer ModelIn the peer model (Figure 9.3), no central brokers or registries exist, but each node (or peer) in the network has its own forwarding list. This list can be based on results learned from previous experience, can be pre-built on initialization, can be a standalone external registry, such as the ones in the centralized model, or a combination of all these. Figure 9.3. The Web services peer model.
A typical scenario would be for a requestor to forward a request to a restricted set of peers, based on capabilities that these peers have declared or that the requestor has learned about them. Each of these peers in turn can either be a potential provider or intelligently forward the request to another set of their peers, based on experience or capability. This cycle is repeated until a provider is found or some kind of preset timeout or forwarding level (time to live) is reached. Again, current technologies such as SOAP Intermediaries, as discussed in Chapter 3, "Simple Object Access Protocol (SOAP)," and WSDL can be used to implement a basic level of this kind of architecture, but they lack the next level of intelligence and semantics to make them truly and seamlessly interoperable with no necessity for user intervention. Further VariationAlthough, as mentioned, these two models might be extremes on the spectrum, Web services architectures will probably end up being a combination of the two, with independent peer nodes looking to some well-known brokers as needed. In addition to the maturing of the Web services model, there will be increasing levels of complexity and variation in the different components of this vision, as current technologies mature and new technologies are created. For example, the process of expressing a need into some form of formal machine-understandable request can have various levels of automation and intelligence. The origin of the trigger itself can also be examined: Is it due to a user's action, an automated set of business rules, a networked device such as a cell phone, or an autonomous software agent's decision? The process of routing that request to possible fulfillers is also a prime target for enhancement. In addition to the relatively static keyword searching provided by UDDI, for example, how can the meaning of the request be maintained and conveyed to different services, and how can the original intent of the requestor be maintained? The same can be said about the process of negotiation between requestor and potential providers: What negotiation protocols will they follow, and how will they ensure that they are speaking the same language and that the terms they are using, although similar, actually mean the same thing? How will they prove their identities to each other and come to an enforceable agreement? Finally, in a recursive model of "Web services all the way down," how can these services in turn automatically find and compose other services to fulfill a particular goal? And, once the agreement is in place, how and where will the service be executed? Although some of the mechanisms that answer these questions are already in place—and covered in this book, such as SOAP and SOAP Intermediaries (see Chapter 3), encryption and digital signatures (see Chapter 5, "Using SOAP for e-Business"), WSDL (see Chapter 6), and UDDI (see Chapter 7)—or are being developed, we are far from the full vision of automated Web services everywhere. The next few sections will introduce some of the current work on these topics. |
|
|