| [ Team LiB ] |
|
XML ParsersWe've now written our first XML document, which describes an email. The next thing we need to do is to actually process the document and display it on the screen. The screen should display all the components of an email as described in the XML document. We've seen that the XML document is quite easy to read with the naked eye because it provides a definite structure to your data. But how do you make a software application read your XML document? To do so, you must use some tool that will parse through the file and give access to the contents of the document in a convenient format, which can then be handled using other applications. You'll find a variety of such tools in the market. They're known as XML parsers. Parsers are of two types:
You need to have an XML parser in your classpath in order to work with the examples for this chapter. You can easily get a parser from the Internet. Several free parsers are available. The choice of which parser you want to use depends on two factors: the conformity of the parser to the XML specification and the speed of parsing. NOTE Some of the sites where you can find free XML parsers on the Internet are
WebLogic Server comes bundled with the Apache Xerces parser. Thus, you don't need to download the parser separately for the sake of the examples given in this chapter. For the rest of this chapter, we'll assume that you're using the bundled Xerces parser. The next step is to use the APIs associated with XML parsers to parse your XML document. There are several APIs that you can use to parse XML documents. Two of the most common XML parsing APIs are SAX and DOM. In the following sections, we'll learn how to use these APIs to parse and use your XML documents. Let's use the email XML document for parsing (see Listing 29.5). Listing 29.5 The Email XML Document
<?xml version="1.0"?>
<!DOCTYPE email SYSTEM 'EMail.dtd'><email>
<from name="John Doe" id="johndoe@xyzcompany.com"/>
<to name="Jane Doe" id="janedoe@xyzcompany.com"/>
<to name="SomeOther Doe" id="someotherdoe@xyzcompany.com"/>
<cc name="YetAnother Doe" id="yetanotherdoe@xyzcompany.com"/>
<subject>Hello!</subject>
<options>
<read_receipt/>
<priority type="Normal"/>
</options>
<body>
Hello how are you doing.
</body>
</email>
SAXSAX stands for Simple API for XML. It began as a Java-only API, but you can currently find SAX-based parsers for other languages. Different parsers implement the common SAX interfaces; any application written using this API is guaranteed to work with different parsers as long as the application and the parsers conform to the specifications of the interface. The Apache Xerces parser that's bundled with WebLogic Server supports SAX version 2.0. SAX parsers generate events based on your XML document. Your application will provide handlers to handle the events generated by the SAX parser. Examples of events include start and end of an element, and so on. This section is intended to provide an introduction to the SAX API. You can parse your XML documents with a SAX parser by using a SAX reader. A SAX reader is any class that implements the interface org.xml.sax.XMLReader. This class is provided by the implementation of the SAX parser. The class we'll use that implements this interface is weblogic.apache.xerces.parsers.SAXParser. This class and other interfaces that we'll use are available in the weblogic.jar library of your WebLogic installation. Be sure to include this file in your classpath to execute any examples given in this chapter. The following sections describe the various steps involved in parsing an XML document using the SAX API. Instantiate the ReaderThe first step in using a SAX parser is instantiating the SAX reader. This is done by using a reader factory class, org.xml.sax.helpers.XMLReaderFactory. This factory is capable of generating different SAX readers for you, based on certain parameters. You can invoke the createXMLReader method on this factory and pass to it the name of the class you want to instantiate. Alternatively, you may also specify this name in the environment variable org.xml.sax.driver and not pass any parameters to the createXMLReader method. XMLReader aReader = XMLReaderFactory.createXMLReader ("weblogic.apache.xerces.parsers Parsing the DocumentAfter you've instantiated an XMLReader instance, you can pass the XML document into the reader and request it to parse the document by invoking the parse method on the reader. The document can be passed in as an instance of org.xml.sax.InputSource. This object encapsulates several useful pieces of information about the represented document. You may create an InputSource object either by passing to it an URI that identifies the document or by passing a IDs java.io.InputStream or java.io.Reader object that resolves to the XML document. The difference between these mechanisms is that when invoked with a URI, any relative system specified with respect to the XML document are resolved automatically. If invoked using the InputStream or the Reader objects, you must explicitly set the system ID by using an appropriate setter. For example, the following block of code parses the email document:
InputSource inputSource = new InputSource("d:/temp/email.xml");
aReader.parse(inputSource);
When the parse method is invoked, it initiates the parsing of the XML document. At this time, your application can receive events generated by the parser and handle them appropriately. The parse method throws an exception of type org.xml.sax.SAXException if it encounters any error while parsing. For example, if your XML document isn't well formed, the parser generates this exception. The event handler (that you code) can also optionally generate this exception to indicate errors. Your application must catch this exception and handle it. Content HandlerIn the previous section, we saw that the parse method of the XML reader object generates events. Your application can trap these events and handle them by using a content handler. A content handler is a class that implements the interface org.xml.sax.ContentHandler. This interface specifies several callback methods, which will be invoked by the parser at appropriate times. You code into these callback methods to handle the events appropriately. In this section, we look at the different methods that must be implemented by your content handler implementation. Note that several of the callback methods throw an exception of type SAXException. You can report any problems with the XML from your callback methods as a SAXException. The client will catch this exception and handle it. The following list describes the different callback methods in the handler class:
Initialization code can either be put in the constructor, or the setDocumentLocator or startDocument methods. If you put initialization code in the constructor, it will be called only once when the class is instantiated, before any kind of processing is done. If you put it in the startDocument method, the parser has already started parsing your document. If your application can handle it, you should choose to put your initialization code in this method. If you absolutely must perform initialization routines prior to the parsing, setDocumentLocator might be a good place. It's a good idea to avoid overloading the setDocumentLocator method, because, as the name suggests, it is meant to be a mutator method. Overloading it with initialization code might not be a good idea. Similarly, finalization code may be put either in the endDocument or the finalize methods. The finalize method is called only once: upon garbage collection of the parser object. This method might not always be called, however (see http://java.sun.com/j2se/1.4.2/docs/api/java/lang/Object.html#finalize()), so be careful what you put in there. In most cases, endDocument should work perfectly well. Now that we've defined a content handler, how do we tell the parser which content handler to use? We do this by invoking the setContentHandler method on the XMLReader prior to invoking the parse method. Thus, the complete listing that parses the document would look as follows: XMLReader aReader = XMLReaderFactory.createXMLReader(DEFAULT_PARSER); aReader.setContentHandler( new EMailContentHandler() ); InputSource inputSource = new InputSource(xmlFile); aReader.parse(inputSource); Let's briefly look at how this handler has been constructed and how it works. Look at the source code listing for the email handler: package com.wlsunleashed.xml.sax; import com.wlsunleashed.xml.sax.email.EMail; import com.wlsunleashed.xml.sax.email.EMailAddress; import com.wlsunleashed.xml.sax.email.EMailOptions; import org.xml.sax.Attributes; import org.xml.sax.ContentHandler; import org.xml.sax.Locator; import org.xml.sax.SAXException; public class EMailContentHandler implements ContentHandler { /** The e-mail object */ private EMail eMail = null; /** Provides information about the parsing process. */ private Locator documentLocator = null; /** A temporary string buffer to hold the contents of elements */ private StringBuffer contentString = null; public void setDocumentLocator(Locator locator) { documentLocator = locator; } public EMail getEMail() { return eMail; } public void characters(char[] chars, int start, int end) throws SAXException { contentString.append(chars, start, end); } public void endDocument() throws SAXException { System.out.println("Processing has ended!"); } public void endElement(String namespaceURI, String localName, String qName) throws SAXException { if (localName.equals("subject")) { eMail.setSubject(contentString.toString()); contentString = new StringBuffer(); return; } if (localName.equals("body")) { eMail.setBody(contentString.toString()); contentString = new StringBuffer(); return; } } public void endPrefixMapping(String prefix) throws SAXException { } public void ignorableWhitespace(char[] chars, int start, int end) throws SAXException { System.out.println("ignorableWhiteSpace " + documentLocator.getLineNumber() + " - " + documentLocator.getColumnNumber() + " - " + start + " - " + end); } public void processingInstruction(String target, String data) throws SAXException { } public void skippedEntity(String entityName) throws SAXException { } public void startDocument() throws SAXException { System.out.println("Processing begins .. "); eMail = new EMail(); } public void startElement(String namespaceURI, String localName, String qName, Attributes attributes) throws SAXException { if (localName.equals("from")) { eMail.setFromAddress( new EMailAddress(attributes.getValue(0), attributes.getValue(1))); return; } if (localName.equals("to")) { eMail.addToAddress( new EMailAddress(attributes.getValue(0), attributes.getValue(1))); return; } if (localName.equals("cc")) { eMail.addCcAddress( new EMailAddress(attributes.getValue(0), attributes.getValue(1))); return; } if (localName.equals("options")) { eMail.setOptions(new EMailOptions()); return; } if (localName.equals("read_receipt")) { eMail.getOptions().setReadReceipt(true); return; } if (localName.equals("priority")) { eMail.getOptions().setImportance(attributes.getValue(0)); return; } if (localName.equals("subject") || localName.equals("body")) { contentString = new StringBuffer(); return; } } public void startPrefixMapping(String prefix, String URI) throws SAXException { } } We have an Email object along with an accessor method for it. After completing the parsing, the requesting class can get a hold of this Email object by using the accessor method. This object is built up using the contents of the email XML file. In the setDocumentLocator method, we first accept the document locator instance and store it locally. This will be useful to get document-related information later on, if we implement detailed error reporting, and so forth. We initialize the local variables in the startDocument method. And in the startElement method, we begin filling in the contents of the Email object whenever we receive an event. The event type is identified using the local name of the event tag. Any attributes of that tag is obtained from the Attributes object. In this simple implementation, we take the order of attributes for granted and hard-code the indexes. TIP In practice, you should define constants to define these indexes. Better still, if you cannot guarantee the order of attributes, you should write code to scan for the name of the attribute before processing it. Note the special processing for the subject and the body tags. The startElement method does nothing for these two tags. It simply initializes a local variable called contentString. This string is populated using the characters method, as shown in the code. Finally, when the endElement method is invoked, it populates the Email object with the contents of the contentString variable. The handler is very stateful in nature. It must always be aware of the location of the tag with respect to the whole XML document. This is because the same tag name may be used in different sections of the same document, and may provide different meanings. Therefore, the handler should always be aware of the state under which the particular tag is being processed. Complete source code that parses the email XML is provided on the CD at the end of the book, in the folder for this chapter. You can execute the class com.wlsunleashed.xml.sax.EMailClient and pass the Email.xml file to it. This class displays the contents of the Email XML document in a simple Swing-based client. Play around with this example a little bit; try changing the XML document and see how that affects the output. Error HandlerYou can specify a custom error handler that will be called whenever an error occurs during the parsing process. This will enable you to handle errors in an appropriate way and either allow processing to proceed or stop processing completely. A class that has to act as an error handler should implement the org.xml.sax.ErrorHandler interface. This interface specifies three methods: error, fatalError, and warning. Each of these methods takes a SAXParseException as a parameter, and can throw a SAXException. The SAXParseException object contains the line number on which the error occurred, the URI of the document that caused the error, and details about the exception, including the message and a stack trace. The error handler can handle these messages in an appropriate way. Warnings are reported using the warning callback method, whereas nonfatal errors are reported using the error method. The default behavior is to continue parsing the document after this method has finished processing. But if the method implementation decides to stop processing, it can throw a SAXException from either of these methods and the parser will stop processing the document. On the other hand, when a fatal error occurs, the parser invokes the fatalError method and will then stop processing as specified by the XML specification. Validation errors are typically reported as nonfatal errors, whereas an XML document that is not well formed results in a fatal error. Refer to the file com/wlsunleashed/xml/sax/EMailErrorHandler.java, that is included in the CD for a sample implementation of the ErrorHandler interface. In this example, we print out all warnings, errors and fatal errors, but intercept warnings. For errors and fatal errors, we throw a new SAXException object, which essentially halts processing. The source is listed here:
public class EMailErrorHandler implements ErrorHandler {
public void warning(SAXParseException warn) throws SAXException {
// We shall print out all warnings and ignore them
printException(warn);
}
public void error(SAXParseException error) throws SAXException {
// print out the error & exit
printException(error);
throw new SAXException(error);
}
public void fatalError(SAXParseException error) throws SAXException {
// print out the error & exit
printException(error);
throw new SAXException(error);
}
private void printException(SAXParseException exception) {
System.out.println("Error occurred while parsing the XML document");
System.out.println("Line # = " + exception.getLineNumber());
System.out.println("Column # = " + exception.getColumnNumber());
System.out.println(exception.getMessage());
System.out.println("Stack Trace");
exception.getCause().printStackTrace();
}
}
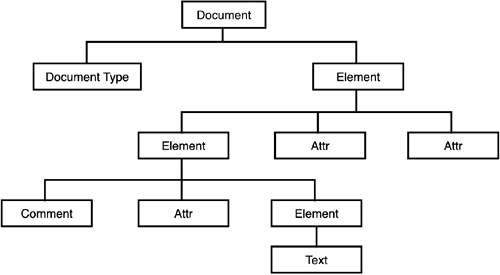
Other SAX 2.0 FeaturesIn addition to the features of the SAX API discussed here, SAX 2.0 also supports some additional features. You can use SAX 2.0 methods to get and set feature flags and property values in XML readers. The feature flags and property values affect the way the XML reader behaves while parsing your XML, such as during validation. You can read more about the advanced features of SAX 2.0 by visiting the official SAX Web site at http://www.saxproject.org. There are also two more types of handlers that you can define, one for resolving entitiesif you want the flexibility of overriding the default entity resolution processand another for handling callbacks when advanced DTD features such as notations and unparsed entities are encountered by the parser. We aren't going to discuss these features in this chapter for the sake of brevity. Default HandlerAfter discussing all these handler methods, we now know that the specification enables us to define a bunch of callback methods. That's very flexible, but can be quite painful if all you need are a couple of these methods and not all of them. In such cases, your handler can extend the org.xml.sax.helpers.DefaultHandler class. This class provides default implementations for all the methods in all the four handler interfaces. Your handler class may then override only the methods that you require for your application, thus keeping your code clean. XML Parsing Using DOMAnother common XML parsing API is the DOM API. DOM stands for Document Object Model. DOM is a standard that was developed by the World Wide Web Consortium (W3C) (unlike SAX, which evolved based on discussions on mailing lists). DOM was not designed for Java alone, and you can easily find DOM-based parsers for any language. But, of course, we'll be dealing with a DOM parser for Java here. In this section, you get a basic overview of the DOM specification. It isn't intended to be a comprehensive discussion on the features of DOM. You can very easily find books that discuss DOM in detail. A good place to learn basic DOM is the URL http://www.w3schools.com/dom. A DOM parser converts an XML document into an object model, which can then be accessed using standard APIs by your applicationhence the name Document Object Model. As mentioned earlier, DOM is intended to be cross platform; therefore, it's very easy to find parsers written in several languages that subscribe to the DOM way of handling XML. DOM standardizes concepts into levels rather than versions. The latest level of DOM specification is Level 3. WebLogic Server ships with a Xerces DOM parser that is based on the DOM Level 2 core specification, with some Level 3 features. The Basics of DOMSAX gives you a piecemeal representation of the XML document. It makes the data available to your application one piece at a time. DOM, on the other hand, does not do that. After parsing the document, DOM provides all the data as a tree of objects to your application at one go. All the data is loaded in memory in the object model, and your application receives a reference node of this model. You can then navigate through this model using the API to get to the actual data. Remember that the DOM specification does not outline the methods involved specifically, rather it simply focuses on the model of the document. The object model consists of the XML data represented in a tree format. The tree is built using components called nodes, represented by the interface org.w3c.dom.Node. All the objects of the tree implement this interface. The root node of the DOM tree is known as the Document node, and is represented by using the object org.w3c.dom.Document. Other objects such as Element, Attr, Text, and so on make up the entire DOM object model. An example DOM structure is represented in Figure 29.1. Figure 29.1. The DOM structure representation.
As you can see from the figure, the tree model is very strictly followed in a DOM representation. For example, the Text node is a child, rather than an attribute, of the Element node. This is to maintain the strict tree structure of the model. All the nodes implement the same Node interface, so you can use the basic navigation methods present in this interface on any type of node without worrying about what type it is. Navigation methods include methods such as getParent, getChildren, and so forth. One important point is that a method such as getChildren does not return a Java collection. It returns custom collections such as NodeList and NamedNodeMap, which are essentially part of the DOM classes. Parsing an XML FileParsing an XML document using DOM is quite straightforward: instantiate the parser and parse the document. You can then query the parser to get a handle to the in-memory Document object that was created while parsing the document. The following code snippet parses an XML document: DOMParser aParser = new DOMParser(); aParser.parse(xmlFile); Document doc = aParser.getDocument(); When you actually code this and try to compile this code, your compiler will complain about catching two exceptions. The first is java.io.IOException, which will be thrown if there are any I/O errors while accessing the XML document. That is perfectly understandable, but the second exception that your compiler will complain about is SAXException! Now this is definitely strange behavior! As strange as it might seem at first, remember that although the DOM model gives you a complete tree representation of your XML document, it does not specify how the parser should construct the tree. The tree can surely be constructed using an underlying SAX parser and then handed over to you. Because there's no specified standard describing how this should be done, it is quite common for DOM parsers to use SAX to construct the model. Processing the Document TreeThe getDocument method returns a Document object, which is essentially the handle to the object model for your application. You might also find parsers that will return the Document object directly from the parse method without you having to explicitly invoke the getDocument method. As mentioned earlier, all the objects implement the Node interface. The node interface contains all the relevant methods that enable you to navigate the tree and get to the data. The first step in identifying the data is to identify the type of the node you're dealing with. You can do this by invoking the getNodeType method on the Node interface. This returns an integer value that corresponds to the different node types, as indicated in Table 29.3. All these integer values are defined as constants in the Node interface.
After you've identified the node type, you can access the data contained in the node by invoking the appropriate methods on the object. For example, the getNodeName method returns the name of the element. The getChildNodes returns a list of child nodes to this node (class NodeList). The getAttributes method returns a list of attributes for an element node (class NamedNodeMap). Each attribute implements the Node interface again, and the getNodeName returns the attribute name. The getNodeValue method returns the value of the attribute. In some cases, you can cast the object to an appropriate type to get more specific data. For example, for processing instructions, you can cast the Node to a ProcessingInstruction interface, and access the target and the data by invoking the getTarget and getValue methods, respectively, although the same information can be obtained in a less-intuitive way by using the getNodeName and getNodeValue methods. Similarly, you may cast a document type node into a DocumentType object, and access the public and system IDs by invoking the getPublicId and getSystemId methods. You can look at a working example of using a DOM parser by compiling and executing the class com.wlsunleashed.xml.dom.XMLTreeViewer. This class creates a DOM tree out of any given XML file and displays a tree view on a frame. Although the code is interspersed with Swing calls to draw the tree, the use of the DOM classes should be quite clear from looking at the example. Modifying the DOM TreeWe now know how to access a DOM tree constructed using a DOM parser. It's equally easy to change the contents of a DOM tree. You might remember that with SAX, you can only read the datait isn't possible to change it. But DOM is mutable, and this gives you a very good reason for using DOM rather than SAX when you need this flexibility. DOM can be used to hold and manipulate, both in memory and in XML files, the data of an application. You can create a new document by using the createDocument method on the Document instance. Similarly, the createDocType method can be used for creating a DocType element. Also, there are similar methods such as createElement, createTextNode, and createCDATASection to create the appropriate nodes. Nodes may be appended as children to other nodes by using the appendChild node on the Node interface. If you want to use namespaces in your elements, you would use the createElementNS method rather than the createElement method on the Document object. NOTE You might wonder why the createElement method has not been simply overloaded instead of using a method with a specific name. Remember that the DOM specification is not specific for Java. In order to cater to other languages that might not have the flexibility of method overloading, the specification provides for different method names. To modify an existing DOM tree, you can use methods such as removeChild and appendChild on the Node interface to replace nodes. The Element object also has setter methods that may be used to change attributes of the elements. Similar to elements, you can set namespace-specific attributes by using the appropriate methods. You can learn more about these features by visiting the Web site at http://www.devguru.com/Technologies/xmldom/quickref/xmldom_intro.html. Java API for XML ProcessingNow that we've seen some basic XML parsing using SAX and DOM, let's look at an abstraction layer over these parsers created by Sun, known as the Java API for XML processing, or JAXP for short. This abstraction enables you to use parsers in a vendor-neutral way, and also handle some difficult tasks with DOM and SAX with ease. One confusing aspect of JAXP is that Sun's Crimson XML parser is bundled along with the JAXP classes. Having said that, JAXP itself does not include any parsing capabilities. You can access Sun's parser, as well as any other parser such as Xerces, by using JAXP. It cannot parse XML documents without an underlying DOM, SAX, or an other kind of parser. It only provides an easier way to access the parsing capabilities of DOM and SAX parsers. WebLogic Server provides JAXP version 1.1, which supports both DOM level 2 and SAX 2.0 via Xerces 2.1. JAXP and SAXTo understand why JAXP is so useful, look at the following snippet of code that we used earlier on to work with XML parsers: import org.xml.sax.InputSource; import org.xml.sax.SAXException; import org.xml.sax.XMLReader; import org.xml.sax.helpers.XMLReaderFactory; ... String DEFAULT_PARSER = "weblogic.apache.xerces.parsers.SAXParser"; XMLReader aReader = XMLReaderFactory.createXMLReader(DEFAULT_PARSER); aReader.setContentHandler( new EMailContentHandler() ); InputSource inputSource = new InputSource(xmlFile); aReader.parse(inputSource); Obviously, we're tying this code with the WebLogic Xerces implementation of the SAX parser, and that is clearly hard-coded in the code. This means that if you want to start using a different implementation of the SAX parser, you must modify your code to do it. JAXP provides you with a clean and flexible way of avoiding this by letting you use a parser in your code, and picking the parser using system properties. All the JAXP interfaces and classes can be found in the javax.xml.parsers package. Any class or interface that we refer to in this section belongs to this package unless otherwise stated. JAXP provides you with a SAXParserFactory object, which you can use to create the underlying SAX parser. This object uses some system variables to figure out which parser must be created. The newSAXParser method in this object returns a SAXParser object, which can then be used for parsing the document. Remember that the underlying vendor-specific parser does the actual parsing. JAXP only provides a vendor-neutral abstraction to the parsers. import javax.xml.parsers.SAXParserFactory ... SAXParserFactory factory = SAXParserFactory.newInstance(); factory.setValidating(true); SAXParser parser = factory.newSAXParser(); ... How does the factory know which parser to instantiate? It looks into the environment of your application for a property known as javax.xml.parsers.SAXParserFactory. This property is expected to indicate the class to be instantiated. This class and its associated classes and interfaces should be present in your application's classpath. If the factory can find the class, it instantiates it and enables you use it. Note that we set the properties of the parser that we will use in the factory. For instance, we set the property that will make the factory return a validating parser by using the setValidating method of the factory. You can also set other properties (such as setNameSpaceAware) to further define the attributes of your parser. The factory may throw two different types of exceptions. It throws the FactoryConfigurationError when the parser specified cannot be loaded for any reason. It throws the ParserConfigurationException when you request a feature that isn't supported by the underlying implementation of the parser. After you have the SAXParser object, you can parse your document by passing it into the parse method. The SAXParser object that wraps the actual parser can also tell you whether the parser is a validating parser and whether it is namespace-aware by invoking the appropriate methods. Before you parse, of course, you want to set the content handler that handles the SAX events. You can do this by passing in your handlers using an appropriate flavor of the parse method. You can also obtain the underlying parser directly by invoking the getXMLReader method on the SAXParser object. After you get this object, you can set the different handlers directly to it as we've already discussed. You can also set other vendor-specific properties by using the setProperty method on the SAXParser object. This method takes a name and a value. The name is usually a URI that identifies the property. A typical example of a feature name is http://xml.org/sax/features/validation, which indicates whether the parser supports validation. Similarly, you can also retrieve values stored in properties by using the getProperty method. These methods throw the SAXNotRecognizedException if the property isn't recognized and SAXNotSupportedException if the property isn't supported by the underlying parser. JAXP and DOMUsing JAXP with DOM is quite similar to using it with SAX. Instead of a SAX parser factory, we use a document builder factory. The newDocumentBuilder method of this object (the DocumentBuildFactory) returns a document builder (DocumentBuilder) object, which can help you parse the document. As with SAX, you set document builder properties, such as validating and namespace-aware, into the factory before getting the DocumentBuilder object. These methods also throw the same exceptions that the SAX version did. The only noticeable differences between the SAX and DOM versions are simply the types of factory and parser objects that you use. The rest of the code is identical. Like SAX, the DocumentBuilderFactory uses an environment variable called javax.xml.parsers.DocumentBuilderFactory to identify the class to be instantiated for your application. The DocumentBuilder class enables you to parse the document and get a org.w3c.dom.Document object by using the parse methods. There are different flavors of the parse method that you can use depending on your input source. A sample invocation is given here: DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder db = dfb.newDocumentBuilder(); Document doc = db.parse(inputSource); We haven't provided any examples that use JAXP, but as you can see from the discussion, using JAXP is quite straightforward. Take it as an exercise to change the email client and the XML tree viewer that we discussed while talking about SAX and DOM to use JAXP. |
| [ Team LiB ] |
|